Types of Artificial Neural Networks
In our real-world example, we used a “feed-forward neural network” to recognise handwritten numbers. This is probably the most basic form of a NN. In reality, however, there are hundreds of types of mathematical formulas that are used – beyond addition and multiplication – to compute steps in a neural network, many different ways to arrange the layers, and many mathematical approaches to train the network.
And as mentioned, in most cases a specific type of neural network (or a reasonable combination of several architectures) is necessary for the task at hand. Therefore, in this article we want to introduce some of the more commonly used NN architectures and shed some light on their most common use cases.
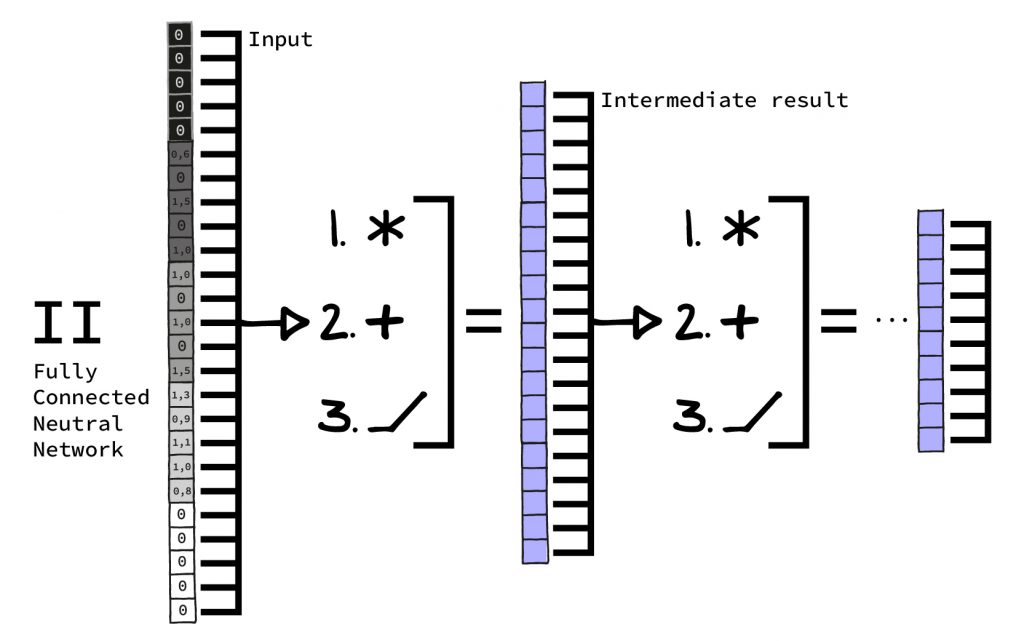
Feed Forward Neural Networks / Fully Connected Neural Networks
This is practically the “bread-and-butter NN”. It’s usually found as part of larger architectures, often in the transition from one part of the architecture to another. In our previous article we have explained in detail how it works, how it is constructed and how it is applied.
If you use it by itself without other, more complex alternatives, it is usually well suited for less difficult problems. Nowadays it is often crucial in order to connect blocks in more complex architectures. Or at the end of a complex architecture, where it allows extracting a result from the “preliminary work” of specialized architectures.
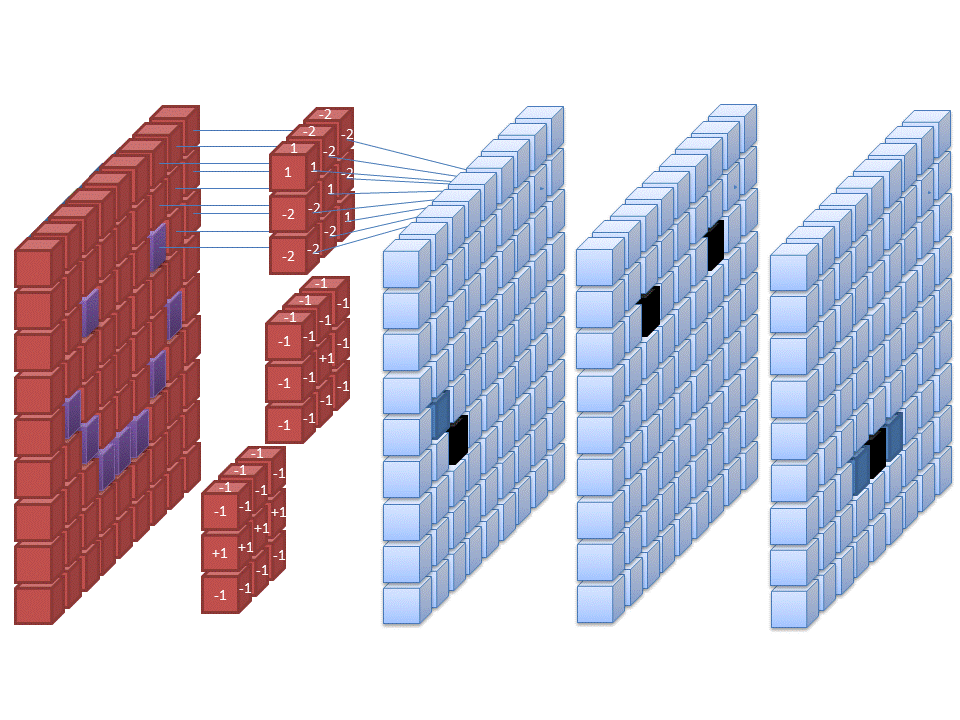
Convolutional Neural Networks (CNN): Image/Voice recognition by convolution
CNN are the hotshots when it comes to image and speech recognition. They give much better results than the simple feed-forward networks from our previous article. Convolutional Neural Networks are (very roughly) inspired by structures in the visual cortex of vertebrates. Mathematically speaking, they use the so-called convolution operation for their calculations. Electrical engineers will feel at home here: CNNs are basically trainable filters in 1D, 2D or 3D.
Recurrent Neural Networks (RNN): Sequences and LSTM
Recurrent neural networks can process sequence data. The best-known example of this class of Neural Networks is the Long-Short-Term-Memory (LSTM). Very often, when data has an ambiguous, varying length (movies, text, audio recordings, stock market prices) RNNs are used. Most of the time they are combined with another network type. For example, a CNN that can handle images can operate together with an RNN on movies.
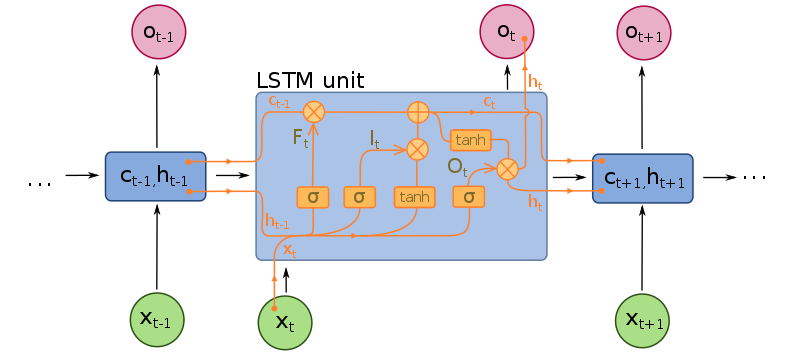
Recurrent neural networks should not be confused with recursive neural networks. The latter exist as well, but at the moment they are rather an academic curiosity and function quite differently than recurrent neural networks.
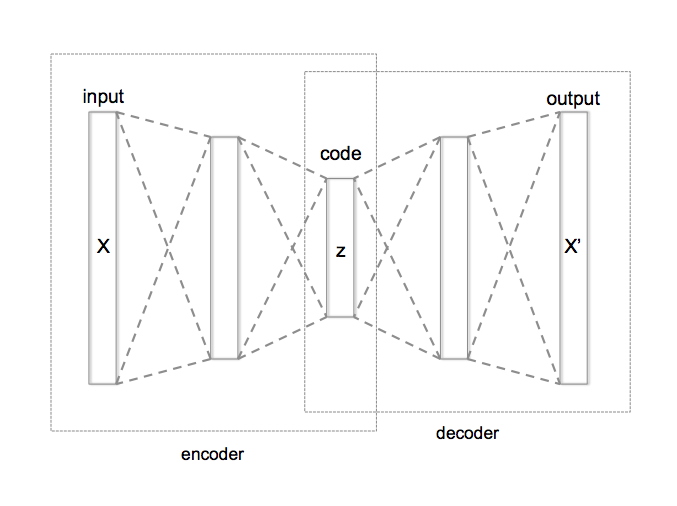
Autoencoder: Unsupervised learning without Output data
Autoencoders are a class of neural networks that do not need fixed labels for learning, so they are particularly suitable for unsupervised learning in neural networks. Autoencoders are a specific way to build and arrange neural networks. In general, any kind of neural network can be transformed into an autoencoder. The advantage of auto-encoders is that they do not need “target data”, so a lot of pre-processing work is saved. The disadvantage of autoencoders is that it is much harder for them to learn something and that there is no guarantee of the learned model being useful.
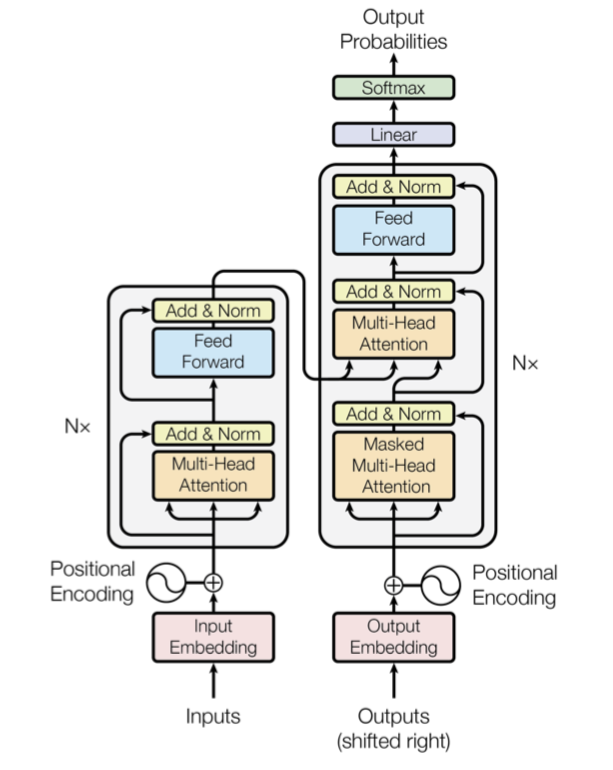
Transformer: Text recognition by Attention Layer
Transformers are still fairly new and the latest big thing when it comes to text processing. Transformers are built from so-called attention layers, which allow the network to understand which parts of the input refer to each other. When one thinks of language, this means sentence fragments referring to each other and complex syntax. Here it quickly becomes evident why transformers are an enormous improvement for the field of text comprehension (and possibly text generation!).
A new layer type, called “Attention”, allows Transformers to selectively correlate inputs.
Neural Networks: Often a combination of different architectures
Ultimately, however, one can say that one architecture rarely comes alone. Most state-of-the-art neural networks combine several different technologies in layers, so that one usually speaks of layer types instead of network types. For example, one can combine several CNN layers, a fully connected layer and an LSTM layer. Maybe even in a way that results in the whole construct to work as an auto-encoder. What is important here – the networks do not grow. The structure is set in stone by a programmer and then trained. The network can’t determine that one layer is superfluous. Neither can it “optimize” itself by removing it.
This was merely a small number of examples – there are still hundreds, if not thousands, of other types of neural network. But the selection presented here is by far the most common one used in practice at the moment. Even if you are not aware of it, you have probably had contact with each of these types of deep learning systems several times already.