Supervised & Unsupervised Learning in ML
In the previous article we introduced the basic concepts of Machine Learning and how the training of an ML model works, using a simple but practical algorithm. Next, we want to take a closer look at the different types of Machine Learning.
ML can be further distinguished based on a variety of aspects. Let’s start by looking at the differences between Supervised and Unsupervised learning in ML.
Supervised vs. Unsupervised Learning
So what do we mean by Supervised and Unsupervised Learning? Looking back at the example from the last post, we see an example of Supervised learning: The correct, expected results of the training data were stored with each piece of data. This way the training algorithm was able to compare its predictions with the actual results and thus improve step by step.
Verifiable data: Supervised Learning
In Supervised learning, training and test data therefore need labels or annotations, i.e. the data has to be correctly evaluated by humans first, as in the cricket example in our previous article. For example, if you want to teach an image classifier to distinguish between dog and cat images, a human must first look at all the training images and decide what is depicted. Otherwise the algorithm would not know whether it is right or wrong and would therefore not be able to adjust its parameters.
Unsupervised Learning - Learning on your own
However, there are also ML methods that can “learn” from data without first being told what the data might mean. This kind of learning is called “Unsupervised Learning”, as the algorithm can learn without supervision by a human “teacher“.
For this, an algorithm is simply fed with the input data. No goal is given towards which to train. This of course makes the data acquisition much easier, because you save a lot of work for the classification of the data! Examples for such algorithms include Clustering and so-called Autoencoders. Unfortunately, these algorithms can only be used in very special cases, which is why most Machine Learning methods used in practice are supervised learning methods.
This explains many companies’ hunger for more and more data, especially when it already contains an annotation. Since the unsupervised methods differ greatly from those presented so far however, we will discuss them in a separate article and will concentrate first on supervised learning.
Different types of Supervised Learning
In Supervised Learning, we always train the model towards a goal previously set (by a human). Depending on the goal, there are different names for the methods. Some learning algorithms can be trained for several goals, others are only fit for one type of goal.
Regression - goal: Numeric predicition
By walking you through the use of linear regression in our last article, we also introduced the first class of monitored ML methods: Regression. Regression is used to predict one or more numerical values. In our example, it was the frequency of crickets’ chirping in relation to temperature.
Examples for Regression values include: Is a specific product review positive oder negative, and how much so (1-5 stars), how much growth do we expect from a stock (given in percent), how long will a construction component last (given in years)?
Classification - goal: Categorization
Another major method is classification. In classification, we establish several possible properties (classes) for our input. The program then sorts our input into those classes, i.e. it assigns properties to input data. If, for example, we want to detect objects on images, a selection of object classes is defined beforehand to which the respective images can be assigned. This could be for example “dog”, “cat” and “mouse”. You could also let the program distinguish (based on other parameters) between “spam email” and “no spam email”.
Any input will be assigned to one of the classes: the computer will always come up with a result, even if there is no dog, cat or mouse in a picture! Also, a classifier can only provide a single result. In practice it is therefore important to interpret the results correctly in order to find out how “sure” the system is about its answer.
Examples for Classification goals: Which object is on the image? Is an email spam or not? Will a user cancel their subscription or not…?
Multi-Label Classification
But what if several recognizable objects appear in one and the same image? In this case we speak of so-called multi-label classification. A suitable system hence does not have to decide on a single answer, but can assign several classes. A picture of a dog and a cat would ideally receive the labels “dog” & “cat”. The program also wouldn’t assign a label to a picture without any animals.
In practice, Multi-Label Classification works just like simple Classification, with the difference that “multiple answers are possible”.
Combining different methods in Supervised Learning
For the development of Machine Learning applications it is therefore essential to know your algorithms well so you pick the right one for a given task. Also it’s crucial to understand how to express complex problems by combining simpler regressions and classifications.
A very intricate example would be the determination of traffic signs in the camera image of a self-driving car: Many different types of objects have to be identified. In addition, however, it must also be determined where these objects are located in the image (and in reality).
Here, a possible hypothetical approach would be to start with a regression to determine the distance of each pixel from the camera (segmentation). In a second step, parts of the image that are connected and the same distance are isolated (this is done with without machine learning by “normal” programming). A classifier then identifies these elements of the image, e.g. stop sign, right-of-way sign, pedestrian sign, etc.
This way you express a complicated problem by combining simple procedures.
Sequences
However, the division into regression and classification only makes sense if one given input corresponds exactly to one specific output. In reality, however, it is often the case that input and/or output do not always have the same every time we use the system.
Complex input values in ML
Just think of automated translation: When you are translating, you can’t just successively replace a word with its corresponding counterpart. Doing that (e.g. by using a classifier that just assigns one output to each input) you would only come up with a mostly nonsensical text. The sentence length of the input in one language can differ greatly from the length of the (correct) output in the other language. So in order to be able to handle a sentence correctly, you have to look at it as a sequence of data that can vary in length. We cannot just create single classifications or regressions for each word or sentence.
For such tasks, we distinguish between various sequence models:
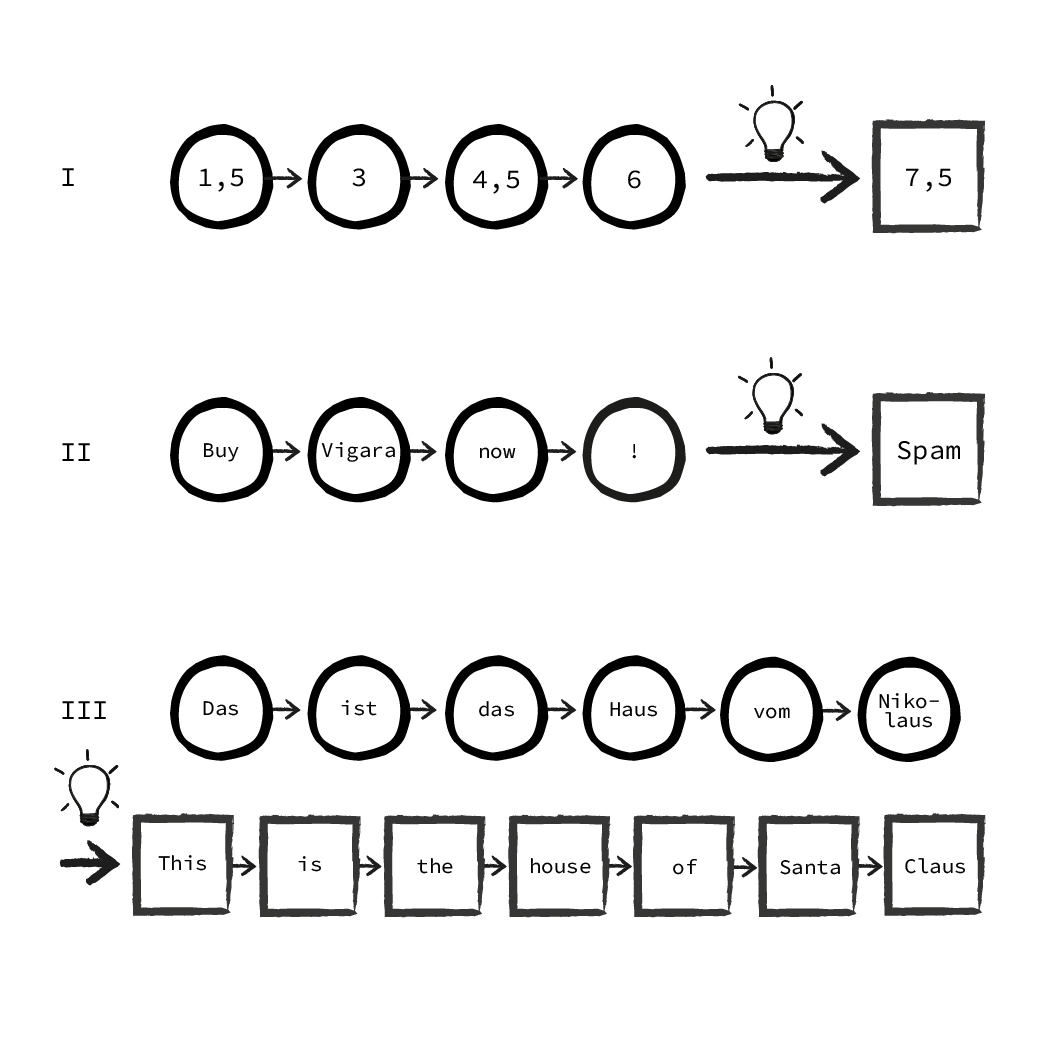
Sequence prediction (I)
The input consists of a sequence (e.g. a series of measured values), while the output is supposed to predict the next value of the sequence. This is the regression in its sequential form. If the input sequence is data that is ordered along a time axis (i.e. each input value in the sequence occurs at a certain moment in time), this is also referred to as “time series prediction”.
Sequence Classification (II)
Like the sequence prediction the input is a sequence of variable length (e.g. words in an email). Based on those, the output is a single classification (e.g. “Email is spam / no spam”). This is the sequence variant of classification.
Sequence-to-Sequence Models (III)
Sometimes both the input and output are sequences of unknown length. Accordingly, the model does not generate one certain output, but a sequence of output(s). The typical example here is translation: The model first looks at an input sequence of which it does not know the length in advance. Based on the input it creates a new sequence in the target language that may have a different length than the input.
These are the most typical variants of sequence models, but there are multiple other combinations of inputs and output possible, creating all sorts of combinations. One can, for instance, decide for an output not to be generated until the entire input has been read (as in translation, III). But the output can also be generated for each step of the input, e.g. when assigning the notes played to an audio recording of a piano piece (V).
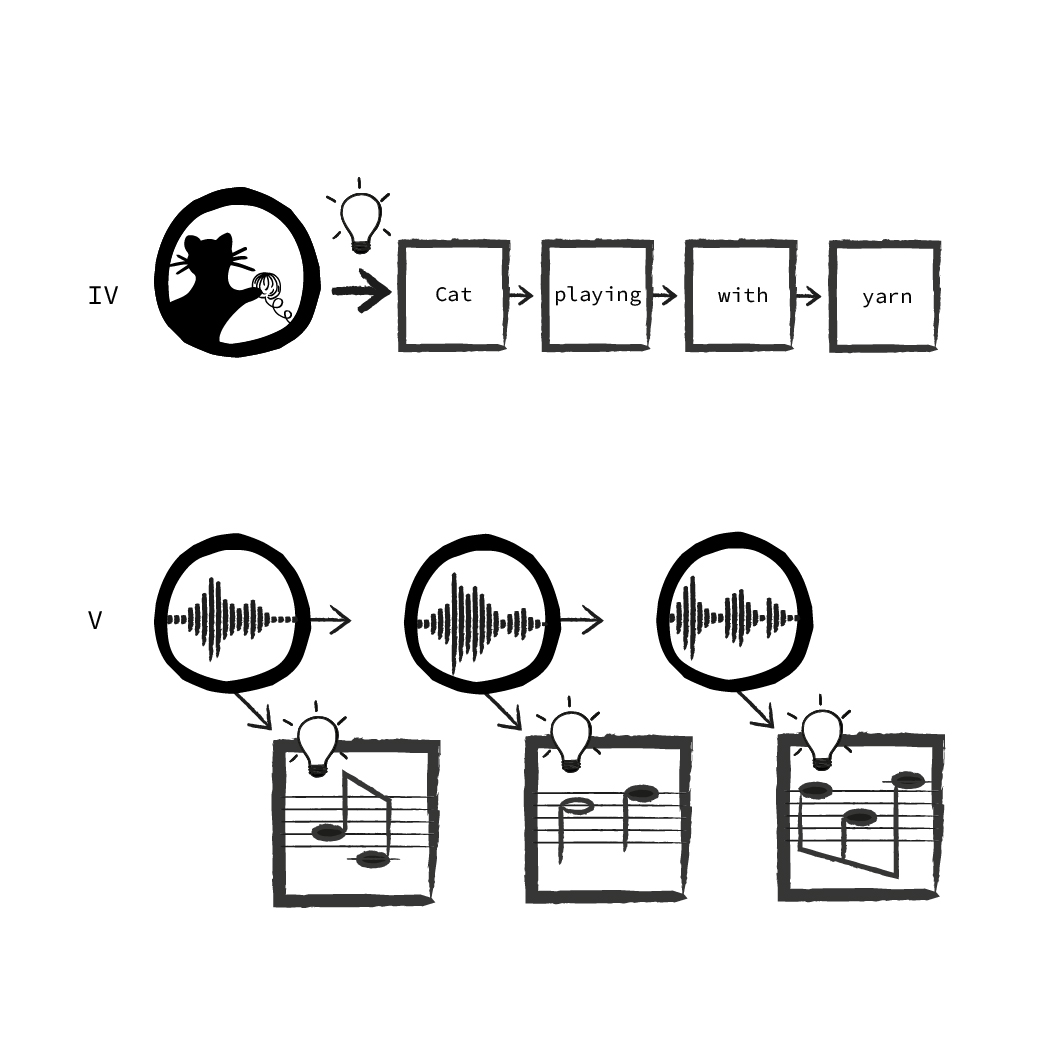
Alternatively, the input can have a fixed size, like a normal regression or classification, while the output may be treated as a sequence. Just think of a neural net creating a description text for an image. The image is first scaled to a fixed pixel size - so the input is guaranteed to always have the same size. The output text, however, is not limited to a certain length and depends on the content of the image. (IV)
Such sequential models are usually much harder to train than models that have “only” a fixed size input and output. If such a task has to be solved, one first tries to simplify the problem and reduce the input and output to fixed sizes. Only if this is not possible, sequential models should be used.
In the next article we will shed some light upon Machine Learning methods that are currently all the rage: Neural Networks and Deep Learning.