Arten von Künstlichen Neuronalen Netzen
In unserem Praxis-Beispiel haben wir zur Erkennung von handgeschriebenen Ziffern ein “feed-forward neural network” genutzt. Dieses ist die wohl einfachste Form eines NN. In der Praxis gibt es jedoch hunderte Arten von mathematischen Formeln, die über Addition und Multiplikation hinaus benutzt werden, um Schritte in einem Neuronalen Netz zu berechnen, viele verschiedene Arten, die Schichten anzuordnen, und viele mathematische Ansätze das Netz zu trainieren.
Und wie erwähnt, braucht es meist den einen passenden Typ Neuronales Netz (oder eine sinnvolle Kombination mehrerer Architekturen) für die entsprechende Aufgabe. Deshalb wollen wir in diesem Artikel einige der häufiger verwendeten NN-Architekturen vorstellen und beleuchten, in welchem Gebiet sie zu Hause sind.
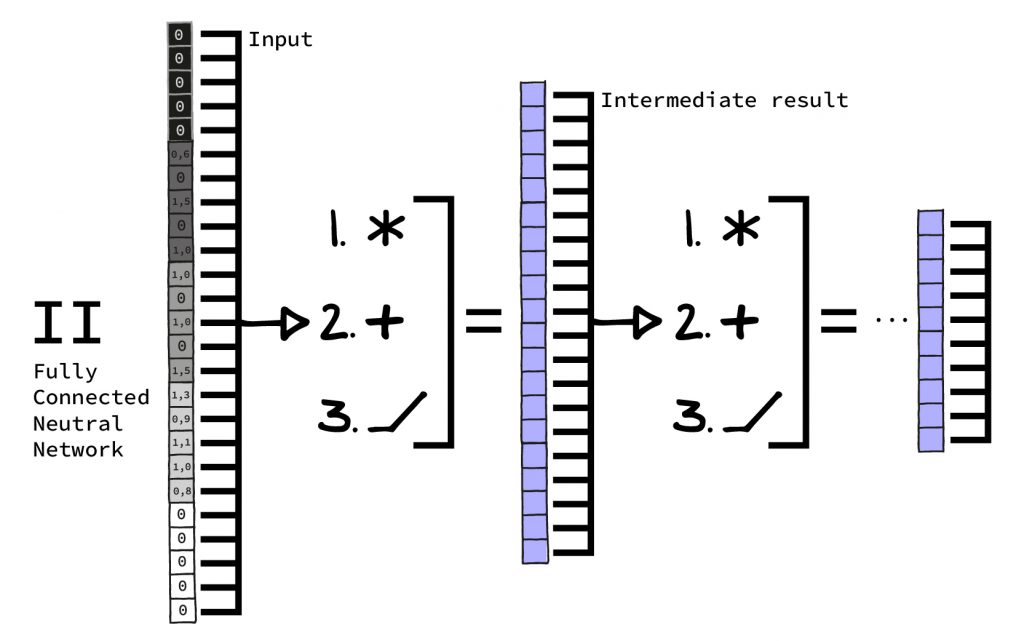
Feed Forward Neural Networks / Fully Connected Neural Networks
Dies ist quasi das „Brot-und-Butter NN“. Dieses findet man besonders häufig als Bestandteil größerer Architekturen, oft im Übergang von einem Teil der Architektur zu einem anderen. Wie es funktioniert, es aufgebaut ist und wie es angewandt wird, haben wir in unserem vorigen Artikel im Detail ausgeführt.
Nutzt man es alleine ohne andere, komplexere Varianten, eignet es sich für einfachere Probleme. Heutzutage ist es oft wichtig, um Blöcke in komplexeren Architekturen zu verbinden. Oder es ermöglicht am Ende einer komplexen Architektur, ein Ergebnis aus der „Vorarbeit“ der spezialisierten Architekturen zu extrahieren.
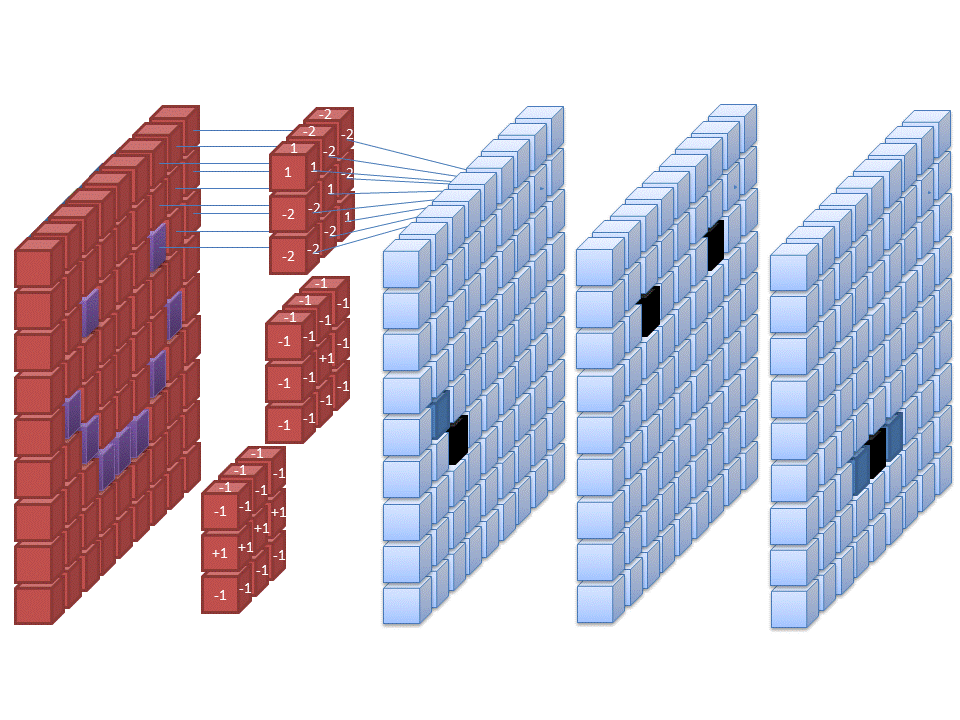
Convolutional Neural Networks (CNN): Bild-/Spracherkennung durch Faltung
CNN sind die Stars, wenn es um Bilderkennung und Spracherkennung geht. Sie liefern wesentlich bessere Ergebnisse als unsere einfachen Feed-Forward Netze aus unserem vorigen Artikel. Convolutional Neural Networks sind (sehr grob) inspiriert von Strukturen im visuellen Kortex von Wirbeltieren. Mathematischer ausgedrückt benutzen sie sogenannte Faltungen für Ihre Berechnungen. Elektroingenieure werden sich hier zu Hause fühlen: CNNs sind im Grunde trainierbare Filter in 1D, 2D oder 3D.
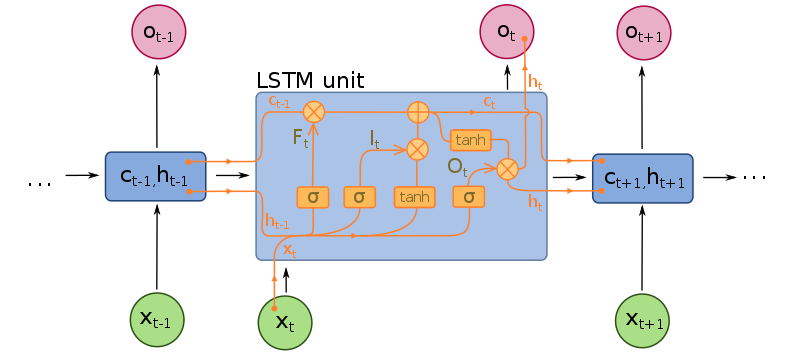
Recurrent Neural Networks (RNN): Sequenzen und LSTM
Rekurrente neuronale Netze können mit Sequenzdaten umgehen. Der bekannteste Vertreter dieser Klasse von Neuronalen Netzen ist das Long-Short-Term-Memory (LSTM). Sehr oft, wenn Daten eine nicht eindeutige, feste Länge haben (Filme, Text, Audioaufnahmen, Börsenkurse) kommen RNNs zum Einsatz. Meistens nehmen sie ein anderes Netz mit ins Boot. So kann ein CNN, das mit Bildern klarkommt z.B. zusammen mit einem RNN auf Filmen arbeiten.
Nicht zu verwechseln sind Rekurrente Neuronale Netze mit Rekursiven Neuronalen Netzen. Letztere gibt es zwar auch, jedoch sind sie momentan eher eine akademische Kuriosität und funktionieren vor allem ganz anders als Rekurrente Netze.
Autoencoder: Unüberwachtes Lernen ohne Zieldaten
Autoencoder sind eine Klasse von Neuronalen Netzen, die keine festen Label zum Lernen brauchen, sich also vor allem für Unüberwachtes Lernen bei Neuronalen Netzen eignen. Autoencoder sind eine bestimmte Art, Neuronale Netze aufzubauen und anzuordnen. Prinzipiell kann man jede Art von Neuronalem Netz in einen Autoencoder verwandeln. Der Vorteil von Autoencodern ist, dass sie keine „Zieldaten“ brauchen, man spart also viel Arbeit bei der Datenvorverarbeitung. Der Nachteil ist, dass es ihnen viel schwerer fällt, etwas zu lernen und es auch nicht garantiert ist, dass das Gelernte nützlich ist.
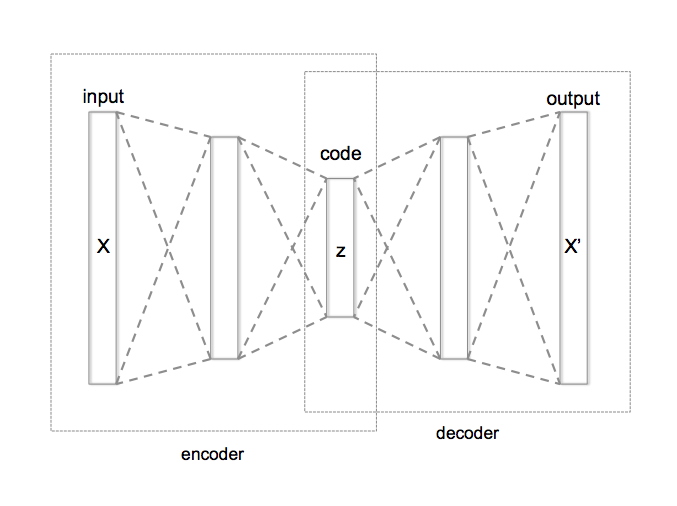
Quelle: https://commons.wikimedia.org/wiki/File:Autoencoder_structure.png
Transformer: Texterfassung durch Attention-Layer
Transformer sind noch ganz neu und der neue Star, wenn es um Textverstehen geht. Transformer sind aus sogenannten Attention-Layern aufgebaut, die es dem Netz ermöglichen, zu lernen, welche Teile eines Inputs zueinander in Beziehung stehen. Denkt man an Sprache, bedeutet dies aufeinander Bezug nehmende Satzteile und komplexe Syntax. Hier wird hier schnell klar, wieso Transformer für das Feld des Textverstehens (und ggf. der Texterzeugung!) ein enormer Schritt sind.
Ein neuer Layer-Typ, „Attention“ (Aufmerksamkeit) genannt, erlaubt es Transformers selektiv Eingaben zueinander in Bezug zu setzen.
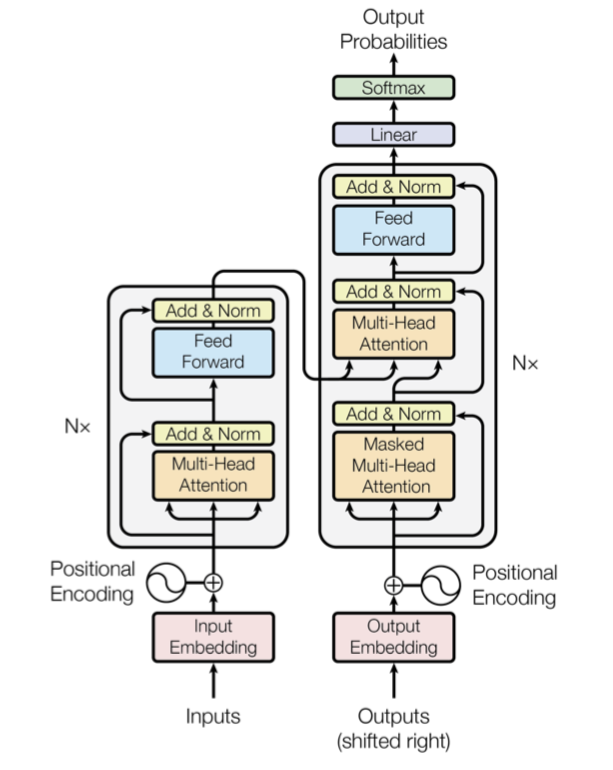
Quelle: Vaswani et. at. „Attention is all you need“
Neuronale Netze: Oft eine Kombination verschiedener Architekturen
Schlussendlich kann man aber sagen: Eine Architektur kommt selten allein. Die meisten modernen Neuronalen Netze kombinieren viele verschiedene Techniken in Schichten, so dass man meist von Layer-Typen statt von Netz-Typen spricht. Man kombiniert z.B. mehrere CNN-Layer, ein Fully-Connected Layer und ein LSTM-Layer. Eventuell das ganze auch noch auf eine Art und Weise, die einen Autoencoder ergibt. Wichtig hierbei – die Netze wachsen nicht. Die Struktur wird durch eine Programmiererin in Stein gemeißelt und dann trainiert. Das Netz kann nicht feststellen, dass es ein Layer nicht braucht, dieses wieder entfernen und sich quasi selbst “optimieren”.
Dies war nur eine kleine Auswahl – es gibt noch hunderte, wenn nicht tausende andere Arten neuronaler Netze. Die hier vorgestellte Auswahl ist aber die mit Abstand wichtigste, die zur Zeit in der Praxis auch Anwendung findet. Auch wenn es Ihnen nicht bewusst ist, haben sie wahrscheinlich bereits mehrfach Kontakt mit jedem dieser Typen von Deep Learning Systemen gehabt.