Überwachtes & unüberwachtes Lernen im ML
Im vorigen Artikel haben wir Grundbegriffe des Machine Learning (ML) kennengelernt und anhand eines einfachen aber praxisrelevanten Algorithmus’ nachvollzogen, wie das Training eines Machine Learning Modells abläuft. Als nächstes wollen wir uns nun die verschiedenen Arten des Machine Learning näher anschauen.
ML kann anhand ganz verschiedener Gesichtspunkte untergliedert werden. Zunächst kann man ML auf einer ganz abstrakten Ebene in Supervised und Unsupervised Learning (auf deutsch Überwachtes Lernen und Unüberwachtes Lernen) unterteilen.
Supervised vs. Unsupervised Learning
Was ist nun mit dem überwachten und dem unüberwachten Lernen gemeint? Wir denken zurück an unser Beispiel aus dem letzten Artikel: Die (korrekten) Ergebnisse der Trainingsdaten, also die Intensität des Grillenzirpens in Relation zur Temperatur, wurden in diesem Fall hinterlegt. So konnte der Algorithmus seine Prognosen mit den tatsächlichen Ergebnissen vergleichen und sich schrittweise verbessern.
Überprüfbare Daten: Supervised Learning
Beim Supervised Learning brauchen die Trainings- und Testdaten also Label oder Annotationen, d.h. die Daten müssen zuvor von Menschen korrekt bewertet werden, wie in dem Grillenbeispiel in unserem vorigen Artikel. Wenn man beispielsweise einem Bilderkenner beibringen will, Hunde- und Katzenbilder zu unterscheiden, muss vorher ein Mensch alle Trainingsbilder anschauen und notieren, was zu sehen ist. Denn sonst wüsste der Algorithmus ja nicht, ob er falsch oder richtig liegt und könnte seine Parameter nicht anpassen.
Unsupervised Learning - Lernprozess auf eigene Faust
Es gibt allerdings auch ML Verfahren, die aus Daten „lernen“ können, ohne dass vorher klar gemacht wird, was die Daten bedeuten sollen. Diese Art des Lernens nennt man „Unsupervised Learning“, also unüberwachtes Lernen.
Hier wird ein Algorithmus einfach mit den Eingabedaten gefüttert. Dabei wird kein Ziel vorgegeben, auf welches hin trainiert werden soll. Das macht natürlich die Datenerfassung viel leichter, da man sich viel Arbeit für das Einordnen der Daten spart! Vertreter dieser Art von Algorithmen sind zum Beispiel Clustering Verfahren oder sogenannte Autoencoder. Leider sind diese Algorithmen nur in sehr speziellen Fällen zu gebrauchen, weshalb es sich bei den meisten in der Praxis eingesetzten Machine Learning Verfahren um überwachtes Lernen handelt.
Dies erklärt den Datenhunger vieler Unternehmen: Ohne Daten gibt es nichts zu lernen. Da die unüberwachten Verfahren sich stark von den bisher vorgestellten unterscheiden, gehen wir auf diese Methoden später in einem separaten Artikel ein und konzentrieren uns zunächst auf das überwachte Lernen.
Verschiedene Arten des Supervised Learning
Beim Supervised Learning trainieren wir also immer auf ein Ziel hin, das zuvor vom Menschen festgelegt wurde. Je nachdem, was für eine Art von Ziel man hat, gibt es für die Verfahren unterschiedliche Namen. Manche Lernalgorithmen können auf verschiedene Ziele hin trainiert werden, andere wiederum sind nur für eine Art von Ziel geeignet.
Regression - die numerische Vorhersage
Mit der linearen Regression haben wir eine erste Klasse von überwachten ML-Verfahren kennengelernt, die Regression, bei der wir einen oder mehrere Zahlwerte vorhersagen. In unserem Beispiel war das die Frequenz des Grillenzirpens abhängig von der Temperatur.
In der Praxis: Welche Werte lassen sich basierend auf den gegebenen Daten ableiten/vorhersagen? Wie positiv oder negativ ist eine Produktbewertung (1-5 Sterne), Wie viel Wachstum erwarten wir von einer Aktie (Angabe in Prozent), Wie lange wird ein Bauteil halten (Angabe in Jahren)…
Klassifikation - die Zuordnung
Eine wichtiges weiteres Verfahren Supervized Learning ist die Klassifikation. Bei der Klassifikation ordnen wir einem Input eine aus einer Auswahl von vorher festgelegten Eigenschaften (Klassen) zu. Wenn wir zum Beispiel Objekte auf Bildern erkennen wollen, wird vorher eine Auswahl von Klassen festgelegt, welcher die jeweiligen Objekte zugeordnet werden können. Dies könnte zum Beispiel „Hund”, „Katze” und „Maus” sein. Man könnte das Programm (basierend auf anderen Parametern) aber auch zwischen „Spam-Email“ und „Keine Spam-Email“ unterscheiden lassen. Jeglichen Input wird ein so trainiertes System einer der Klassen zuordnen. Wichtig hierbei: Es wird immer zu einem Ergebnis kommen, auch wenn weder Hund, Katze oder Maus auf einem Bild sind! Auch kann ein Klassifizierer nur ein einzelnes Ergebnis liefern. In der Praxis ist es daher wichtig, die Ergebnisse richtig zu interpretieren, um herauszufinden, wie „sicher“ sich das System mit einer Antwort ist.
In der Praxis: In genau welche Klasse oder Kategorie fällt ein Input, z.B.: Welches Objekt ist auf dem Bild, Ist eine E-Mail Spam oder nicht, Wird ein User kündigen oder nicht, …
Multi-Label Klassifikation
Was aber, wenn mehrere zu erkennende Objekte in einem Bild vorkommen können? In diesem Fall spricht man von sogenannter Multi-Label Klassifikation. Hier muss sich ein System nicht für eine Antwort entscheiden, sondern kann mehrere Klassen vergeben. Ein Bild von einem Hund und einer Katze würde so im Idealfall die Label „Hund“ & „Katze”. Einem Bild ohne irgendwelche Tiere würde das Programm im Umkehrschluss aber auch kein Label zuweisen.
In der Praxis funktioniert die Multi-Label-Klassifikation genau wie die einfache Klassifikation. Mit dem Unterschied, dass Mehrfachnennungen möglich sind.
Kombination verschiedener Verfahren im Supervised Learning
Für die Entwicklung von Machine Learning Anwendungen ist es also essentiell, die verschiedenen Algorithmen für Überwachtes Lernen zu kennen und zu verstehen, wie man komplexe Probleme durch die Kombinationen von Regressionen und Klassifikationen ausdrücken kann.
Ein sehr komplexes Beispiel wäre zum Beispiel das Bestimmen von Verkehrszeichen in der Kameraaufnahme eines selbstfahrenden Autos: Hier müssen viele verschiedene Objekttypen erkannt werden. Hinzu kommt aber auch: Es muss erkannt werden, wo auf dem Bild (und in der Realität) sich diese Objekte befinden.
Ein mögliches hypothetisches Vorgehen hier wäre, mit einer Regression auf dem Bild zu beginnen, und jedem Pixel zuzuordnen, wie weit es von der Kamera entfernt ist (Segmentierung). In einem zweiten Schritt schneidet man zusammenhängende Bildteile aus und fragt einen Klassifizierer, was auf diesem Teil des Bildes zu sehen ist, z.B. Stopp-Schild, Vorfahrt-Achten-Schild, Fußgänger, usw.
Man drückt also ein kompliziertes Problem durch die Kombination einfacher Verfahren aus.
Sequenzen
Die Einteilung in Regression und Klassifikation macht allerdings nur Sinn, wenn einer Eingabe auch genau eine spezifische Ausgabe entspricht. Oft ist es in der Realität aber so, dass Eingabe und/oder Ausgabe nicht immer die gleiche Größe haben. Was soll man sich darunter vorstellen?
Komplexe Eingabewerte im ML
Denken wir nur einmal an die Automatisierung von Übersetzungen: Beim Übersetzen lässt sich nicht einfach sukzessive ein Wort durch das entsprechende Gegenstück ersetzen. Eine Klassifikation, die “bloß” jeder Eingabe eine Ausgabe zuordnen würde, würde in diesem Fall nur Nonsens-Text generieren. Die Eingabe in der einen Sprache kann in der Länge außerdem stark von der (korrekten) Ausgabe in der anderen Sprache abweichen. Um - in diesem Beispiel - mit einem Satz korrekt umgehen zu können, muss man also als Sequenz von Daten betrachten, die in der Länge variieren kann.
Bei solchen Aufgaben unterscheidet man zwischen verschiedenen Sequenzmodellen:
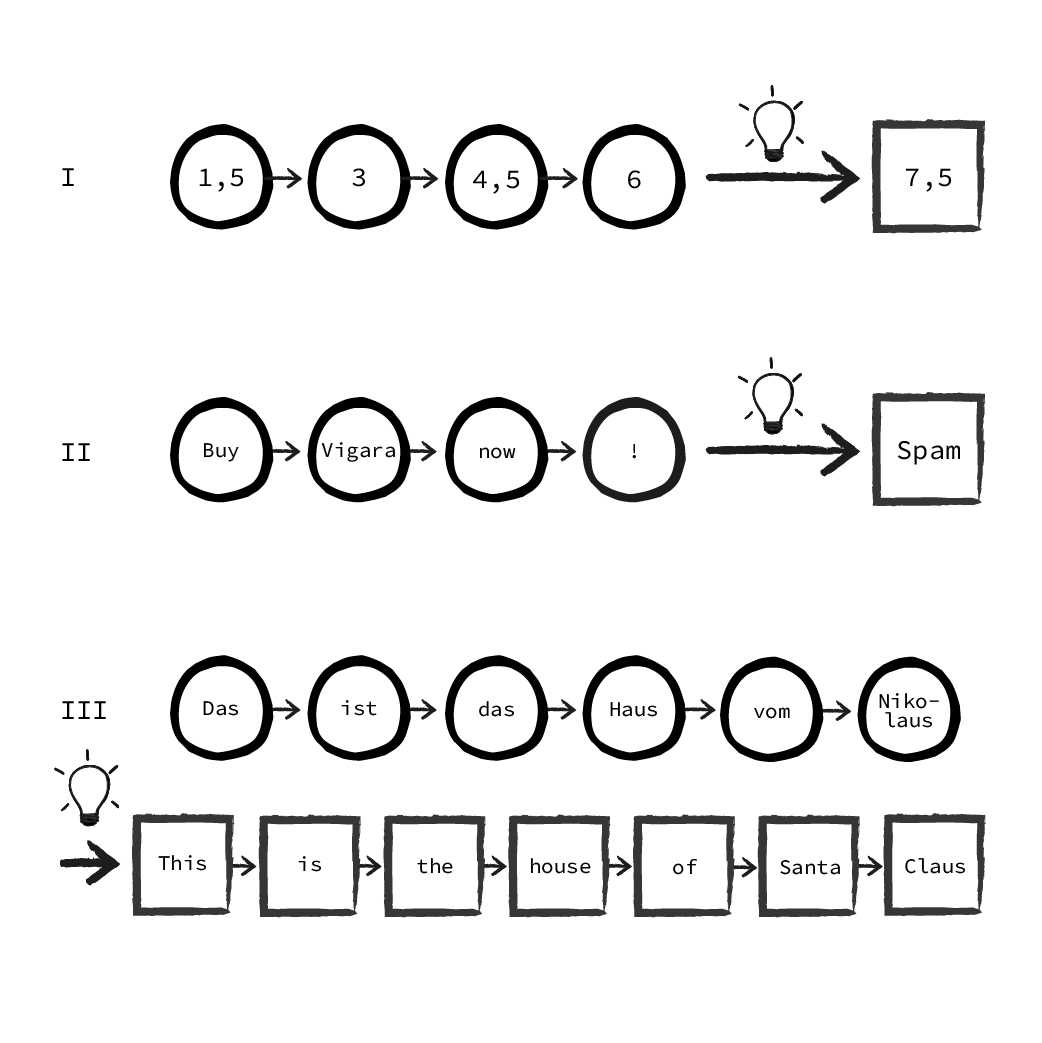
Sequenzvorhersage (I)
Die Eingabe besteht aus einer Sequenz (z.B. einer Reihe von Messwerten), während die Ausgabe den nächsten Wert der Sequenz vorhersagen soll. Dies ist quasi die Regression in Sequenzform. Handelt es sich bei der Eingabesequenz um Daten, die eine zeitliche Reihenfolge haben, spricht man auch von „time series prediction“ (Vorhersage von Zeitreihen).
Sequenzklassifizierung (II)
Die Eingabe ist auch hier eine Sequenz (z.B. Wörter in einer Email). Darauf basierend kommt es bei der Ausgabe zu einer Klassifizierung, z.B. „Email ist Spam / kein Spam“. Das ist die Klassifikation in Sequenzform.
Sequence-to-Sequence Modelle (III)
Eingabe und Ausgabe sind Sequenzen unbekannter Länge. Es wird also nicht eine Ausgabe erzeugt, sondern eine neue Sequenz von Ausgaben. Das klassische Beispiel hier ist die Übersetzung.
Diese Unterteilung lässt sich weiter fortsetzen, man kann alle möglichen Kombinationen erzeugen, hier gibt es aber dann oft keine eindeutige Benennung mehr. Man kann zum Beispiel bestimmen, ob eine Ausgabe erst erzeugt wird, wenn die gesamte Eingabe gelesen wurde (wie bei der Übersetzung, III) oder ob für jeden Schritt der Eingabe eine Ausgabe erzeugt wird, z.B. wenn man einer Audioaufnahme eines Klavierstücks die gespielten Noten zuordnen möchte (V). Alternativ kann auch die Eingabe eine feste Größe haben, die Ausgabe aber als Sequenz gehandhabt werden. Dies ist z.B. der Fall, wenn ein neuronales Netz für ein Bild einen Beschreibungstext erzeugt. Das Bild wird vorher auf eine feste Pixelgröße skaliert, die Eingabe ist also immer gleich groß, aber die Länge des Ausgabetextes steht zunächst nicht fest. (IV)
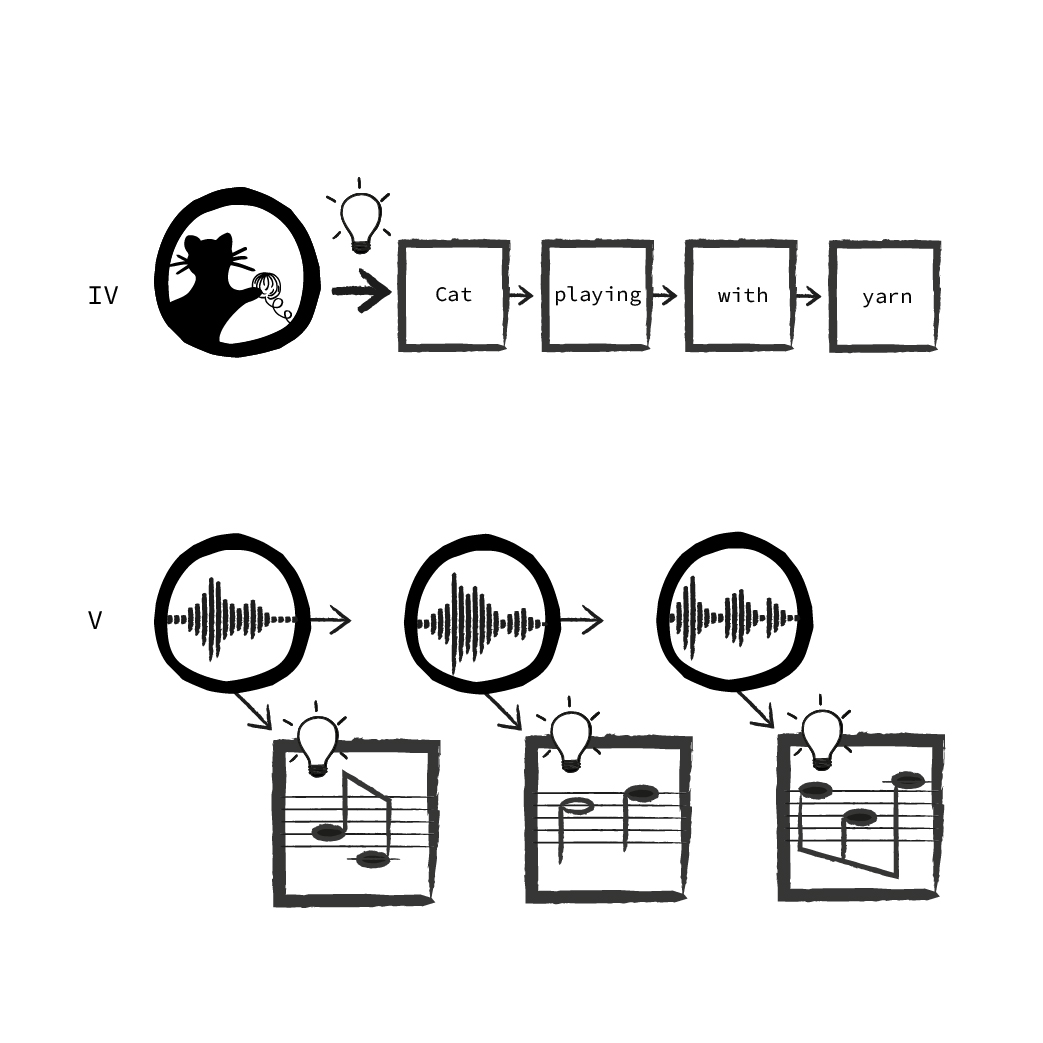
Solche Sequenzmodelle sind meist viel schwerer zu trainieren, als Modelle, die “nur” eine Eingabe und Ausgabe haben. Muss eine solche Aufgabe gelöst werden, versucht man deshalb zunächst, das Problem zu vereinfachen und die Eingabe und Ausgabe auf feste Größen zu reduzieren. Erst wenn dies nicht möglich ist, sollte man auf Sequenzmodelle zurückgreifen.
Im nächsten Artikel kommen wir nun zu den Machine Learning Verfahren, die derzeit in aller Munde sind: Das Thema des kommenden Artikels sind Neuronale Netze und Deep Learning.
FAQs
Was ist Supervised Learning?
Beim Supervised Learning (dt.: Überwachtes Lernen) handelt es sich um eine Trainingsmethode im Machine Learning (ML). Dem Machine Learning Modell werden Trainingsdaten zur Verfügung gestellt, die im Vorfeld korrekt bewertet (annotiert) wurden. Diese Daten ermöglichen es der KI, ihre Ergebnisse zu überprüfen, zu korrigieren und so ein erfolgreiches Training zu durchlaufen.
Was ist Unsupervised Learning?
Das Unsupervised Learning (dt.: Unüberwachtes Lernen) ist eine Möglichkeit im Machine Learning (ML), ein KI Modell zu Trainieren, ohne ein Set von korrekten Trainingsdaten zur Verfügung zu stellen. Der Arbeitsaufwand für den Programmierer hält sich hier also in Grenzen, da keine Daten im Vorfeld aufbereitet werden müssen. Der Algorithmus verarbeitet die Daten ohne ein vorgegebenes Ziel. Beispiele hierfür sind Clustering Verfahren oder Autoencoder.
Was ist der Unterschied zwischen Supervised und Unsupervised Learning?
Während das Machine Learning Modell beim Supervised Learning (dt.: Überwachtes Lernen) mit annotierten Datensätzen trainiert wird (und seine Ergebnisse so korrigieren und sukzessive verbessern kann), trainiert die KI beim Unsupervised Learning (dt.: Unüberwachtes Lernen) mit einem nicht weiter spezifizierten Ziel und mit nicht weiter aufbereiteten Daten.
Welche Arten des Supervised Learning gibt es?
In komplexen Machine Learning Anwendungen werden - angepasst auf die konkrete Aufgabe - häufig verschiedene Verfahren des Supervised Learning kombiniert.
Lineare Regression: Bei der linearen Regression wird versucht, basierend auf vorhandenen Daten einen oder mehrere Zahlwerte vorherzusagen.
Klassifikation: Bei der Klassifikation ordnet die KI den erhaltenen Daten jeweils eine (vorher festgelegte) Eigenschaft (=Klasse). Die Zuordnung einer Eigenschaft basiert auf den ausgezeichneten Trainingsdaten, mit denen das System im Vorfeld trainiert hat.
Multi-Label Klassifikation: Bei der Multi-Label Klassifikation hat das KI Modell die Möglichkeit, dem Input mehrere Eigenschaften zuzuordnen.