Die Grundlagen des Machine Learning
Nachdem wir uns im vorigen Artikel damit beschäftigt haben, wie die klassische KI funktioniert, wollen wir diesmal einen Blick auf das Machine Learning (maschinelles Lernen, auch abgekürzt als ML) werfen.
Bei der klassischen KI wird versucht, ein Problem möglichst exakt zu zerlegen. Nur so können die vom Computer erlernten Antworten (sei es in Form des Entscheidungsbaumes oder einer Tabelle von hinterlegten Lösungen) greifen und das Programm die Aufgabe nachvollziehbar lösen lassen. Dies bedeutet aber auch, dass ein Algorithmus nur ein sehr spezifisches Problem lösen kann. Ändert sich das Problem, so muss der Algorithmus angepasst (oder neu geschrieben) werden.
Genau an diesem Punkt setzt das Machine Learning an. Ziel des Machine Learning ist es, den Computer das Problem Formulieren und Lösen zu lassen - ihn also in die Lage zu versetzen, auch den “unangenehmen Teil” des Justierens und Anpassens selbst zu übernehmen. Möglich ist dies, indem man das Programm mit zwei unterschiedlichen Algorithmen ausstattet, auf die wir gleich näher eingehen werden, nämlich mit einem Lernalgorithmus und einem Vorhersagealgorithmus. Beide zusammen ermöglichen es im Idealfall, viele Probleme mit dem gleichen Verfahren zu lösen, anstatt bei der Programmierung immer wieder bei null anzufangen.
Der Begriff „Lernen“ ist hier übrigens mit Vorsicht zu genießen: Menschen neigen zum Anthropomorphisieren, d.h. wir sprechen nicht-menschlichen Dingen gerne menschliche Eigenschaften zu: Jede hat wohl schon einmal mit ihrem Computer geschimpft - wohlwissend, dass er sie weder hört, noch versteht, was man sagt. Wenn wir nun sagen, Computer (oder besser gesagt: Algorithmen) „lernen”, dann ist die Gefahr groß, diesen Lernprozess wie einen menschlichen Lernprozess zu verstehen. Aber wie wir gleich sehen werden, „lernen“ Maschinen ganz anders als Menschen. Deshalb sprechen die meisten ML-Entwicklerinnen lieber davon, dass sie ihre Algorithmen „trainieren“.
Die wichtigsten ML Begriffe, einfach erklärt
Am besten versteht man wie ML funktioniert, indem man ein Beispiel einmal Schritt für Schritt durchgeht. Um dafür gewappnet zu sein, brauchen wir noch das passende ML Vokabular:
- Algorithmus: Ein Algorithmus ist eine fest definierte, endliche Abfolge von Anweisungen, um eine bestimmte Berechnung durchzuführen. Jedes Computerprogramm besteht aus vielen verschiedenen Algorithmen. Ein Algorithmus kann ganz einfach sein („Finde die kleinste Zahl in dieser Liste von Zahlen“) oder sehr kompliziert („Trainiere dieses neuronale Netz“). Die meisten ML Verfahren bestehen aus zwei Algorithmen: Der sogenannte Trainingsalgorithmus trainiert das Programm mit den verfügbaren Daten, der sogenannte Inferenzalalgorithus wendet die gewonnenen “Erkenntnisse” an und liefert Ergebnisse.
- Parameter: Ein Wert, der beim Training eines Machine Learning Verfahrens gelernt wird. Basierend auf bereits vorhandenen Parametern “trainiert” der Trainingsalgorithmus und versucht, die Parameter immer weiter zu verbessern. Der Inferenzalgorithmus benutzt die Parameter, um Ergebnisse zu berechnen.
- Modell: Ein trainiertes Machine Learning Verfahren. Ein Modell ist hauptsächlich eine (manchmal sehr große) Menge von Parametern und die Information darüber, wie sie benutzt werden müssen - ein abspielbereites ML Verfahren und das Ergebnis des Trainingsprozesses. Der Trainingsalgorithmus erzeugt das Modell, der Inferenzalgorithmus benutzt es.
- Inferenz: Das Ausführen eines Modells mithilfe eines zweiten Algorithmus’. Dieser benutzt das Modell um eine Vorhersage oder Klassifizierung einer Eingabe durchzuführen. Daher auch die Bezeichnung “Vorhersagealgorithmus”. Inferenz ist also ein Fachwort für „ML Modell abspielen und Ergebnis ausspucken“.
Beim Machine Learning benutzt man also die Kombination aus einem Trainings- und einem Vorhersage- oder Inferenzalgorithmus. Der Trainingsalgorithmus benutzt Daten, um schrittweise Parameter zu bestimmen. Die Menge aller gelernten Parameter nennt man Modell, im Grunde ein vom Algorithmus aufgestelltes “Regelwerk”, anwendbar auch auf unbekannte Daten. Der Inferenzalgorithmus nun benutzt das Modell, wendet es auf beliebigen Daten an. Er liefert am Ende die gewünschten Ergebnisse
Ablauf eines Machine Learning Trainings
Mit dem richtigen Vokabular ausgestattet können wir uns den Ablauf eines Machine Learning Projektes näher anschauen:
- Wir wählen das Machine Learning Verfahren aus, für das wir ein Modell trainieren wollen. Die Auswahl hängt vom zu lösenden Problem, den zur Verfügung stehenden Daten, der Erfahrung und auch vom Bauchgefühl ab.
- Danach splitten wir die verfügbaren Daten in zwei Teile auf: Die Trainingsdaten und die Testdaten. Wir trainieren auf den Trainingsdaten und erhalten so unser Modell. Überprüft wird das Modell auf den ihm unbekannten Testdaten. Wichtig hierbei ist natürlich, dass die Testdaten unter keinen Umständen während der Trainingsphase benutzt werden. Der Grund liegt auf der Hand: Computer können toll auswendig lernen. Komplexe Modelle wie neuronale Netze können tatsächlich von selber anfangen, auswendig zu lernen. Die so erzielten Resultate sind zwar ganz wunderbar, basieren aber nicht auf einem vom Programm formulierten Modell, sondern auf den “auswendig gelernten” Daten. Diesen Effekt nennt man „overfitting“.
Die Testdaten sollen aber dazu dienen, bei der Qualitätskontrolle „das Unbekannte“ zu simulieren und zu sehen, ob das Modell wirklich etwas gelernt hat. Ein gutes Modell erreicht ungefähr die gleiche Fehlerrate auf den Testdaten wie auf den Trainingsdaten ohne diese je vorher gesehen zu haben. - Wir benutzen die Trainingsdaten, um mit dem Trainingsalgorithmus das Modell zu trainieren. Je mehr Daten wir haben, desto „stärker“ wird das Modell. Hat man dem Trainingsalgorithmus alle verfügbaren Daten zur Verfügung gestellt, bezeichnet man dies als “Epoche”.
- Das trainierte Modell wird zur Qualitätskontrolle auf die ihm unbekannten Testdaten angesetzt und trifft Vorhersagen. Wenn wir alles richtig gemacht haben, sind die Vorhersagen auch auf unbekannten Daten so gut wie auf den Trainingsdaten - das Modell kann abstrahieren und das gestellte Problem lösen. Nun ist es bereit für den Praxiseinsatz.

Maschinelles Lernen aus der Vogelperspektive:
- Auswahl eines Verfahrens,
- Unterteilung der Rohdaten in Trainings- und Testdaten,
- Der Trainingsalgorithmus trainiert mit den Trainingsdaten,
- Der Inferenzalgorithmus testet mit den Testdaten und macht die gewünschten Vorhersagen.
Machine Learning anhand eines Beispiels - Schritt für Schritt
Nachdem wir die einzelnen Schritte nun theoretisch durchgegangen sind, wollen wir sie nun auf ein konkretes Beispiel anwenden. Anhand des Beispiels wollen wir außerdem den wichtigsten ML Algorithmus vorstellen - die lineare Regression.
Der wichtigste ML Algorithmus: Lineare Regression
Wir haben im Rahmen unseres “Fahrplans” davon gesprochen, dass zu Beginn eines ML Trainings zunächst der passende Algorithmus für das bestehende Problem ausgewählt wird. Den Algorithmus haben wir beschrieben als eine Anleitung, wie der Computer mit bestimmten Daten verfahren soll. Ein besonders wichtiger Algorithmus im Bereich des Machine Learning ist die sogenannte lineare Regression. Hier findet man bereits alle Grundbausteine des ML. Auch wenn andere Verfahren viel komplizierter aufgebaut sind, arbeiten sie alle nach demselben Prinzip. Man kennt die lineare Regression auch aus Tabellenverarbeitungen unter dem Begriff „Trendlinie“.
Was verbirgt sich nun hinter dem eindrucksvollen Begriff „Lineare Regression“? Eine Regression ist eine Problemstellung, die - basierend auf mehreren eingegebenen Variablen oder Werten - am Ende einen oder mehrere numerische Werte “ausspuckt”. Ein Beispiel für eine Regression ist zum Beispiel eine Steuererklärung: Nach Eingabe einer Reihe von Werten, ergibt sich am Ende die zu zahlende Steuer. Oder die Berechnung eines Bremsweges: Eingegeben wird die Geschwindigkeit, ausgegeben der zu erwartende Bremsweg.
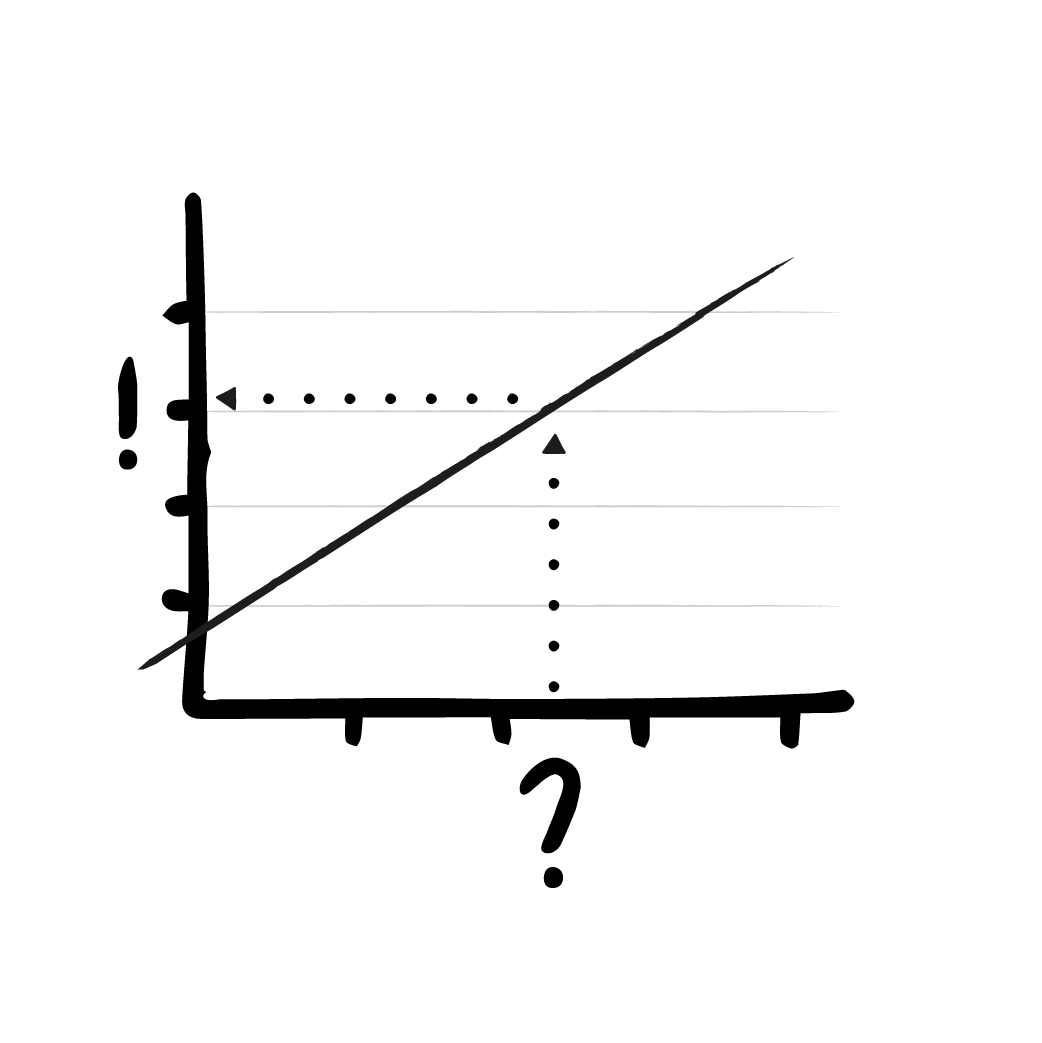
Eine Regression kann also Zahlen vorhersagen. Das „linear“ bezieht sich auf das mathematische Prinzip. Die lineare Regression benutzt lineare Gleichungen, um dies zu tun. Einfacher gesagt: Wir nehmen eine Reihe von bekannten Datenpunkten, versuchen so gut es geht, eine Linie hindurch zu legen und können dann anhand dieser Trendlinie eine Prognose für neue, unbekannte Werte abgeben.
Um die Dinge nicht zu verkomplizieren und für unser Beispiel möglichst gut darstellen zu können, beschränken wir uns an dieser Stelle auf die einfachste Art der linearen Regression, bei der es nur einen Eingabewert und einen Ausgabewert gibt. Ein bestimmter Wert auf der x-Achse resultiert in einem korrespondierenden Wert auf der y-Achse. Die Werte lassen sich als Punkte in einem Koordinatensystem anschaulich darstellen.
Dieses einfache Verfahren besitzt nur zwei Parameter: Es gibt zum einen die Steigung der Geraden und die Verschiebung der Geraden (auch Achsenabschnitt genannt). Diese beiden Werte werden vom Trainingsalgorithmus schrittweise angepasst.
Der Inferenzalgorithmus ist dann auch sehr einfach: Wir nehmen die Eingabe (den x-Wert) und berechnen die Ausgabe, indem wir schauen, was der entsprechende y-Wert der Geraden an dieser Stelle ist.
ML in der Praxis - Lineare Regression Schritt für Schritt erklärt
Wir liegen auf einer Wiese, schauen in den Nachthimmel, lauschen dem Zirpen der Grillen und fragen uns, wie oft pro Sekunde die Grillen auf der Wiese zirpen. Wir haben die Vermutung, dass Grillen (als Insekten) es eher warm mögen und gehen davon aus, dass die Intensität des Zirpens von der Temperatur abhängt. Wir möchten dies nun aber für alle Temperaturen bestimmen, können das Wetter aber nicht steuern, um die entsprechenden Daten einzuholen. Außerdem haben wir keine Lust, Nacht für Nacht mit Mikrofon und Thermometer auf der Lauer zu liegen.
Schritt 1 - Die Wahl des richtigen ML Verfahrens
Wir haben also zwei Messwerte, die linear voneinander abhängig zu sein scheinen. Je wärmer es wird, desto intensiver scheint das Zirpen der Grillen zu sein: Vor unserem inneren Auge sehen wir eine linear steigende Funktion - und entscheiden uns für die lineare Regression als bestes Verfahren!
Schritt 2 - Trainings- und Testdaten für den Trainingsalgorithmus
Um etwas zu “lernen”, braucht unser Trainingsalgorithmus aber wenigstens ein paar Daten. Wir fassen uns also ein Herz, packen unser Mess-Equipment ein, besuchen die Wiese und sammeln die Trainings- und Testdaten für unser ML Verfahren. (Oder wir laden die Daten einfach hier herunter). Bevor wir das Modell mit den ersten Daten “füttern”, wird es zunächst mit zufälligen Parametern initialisiert. Die Parameter des Modells sind zu Beginn Zufallszahlen oder Nullen (je nach Parameter und ML Verfahren). Ohne, dass irgend etwas gelernt wurde, kann das Modell nun immerhin schon Werte ausspucken, ohne abzustürzen. Allerdings sind diese Werte natürlich total falsch.
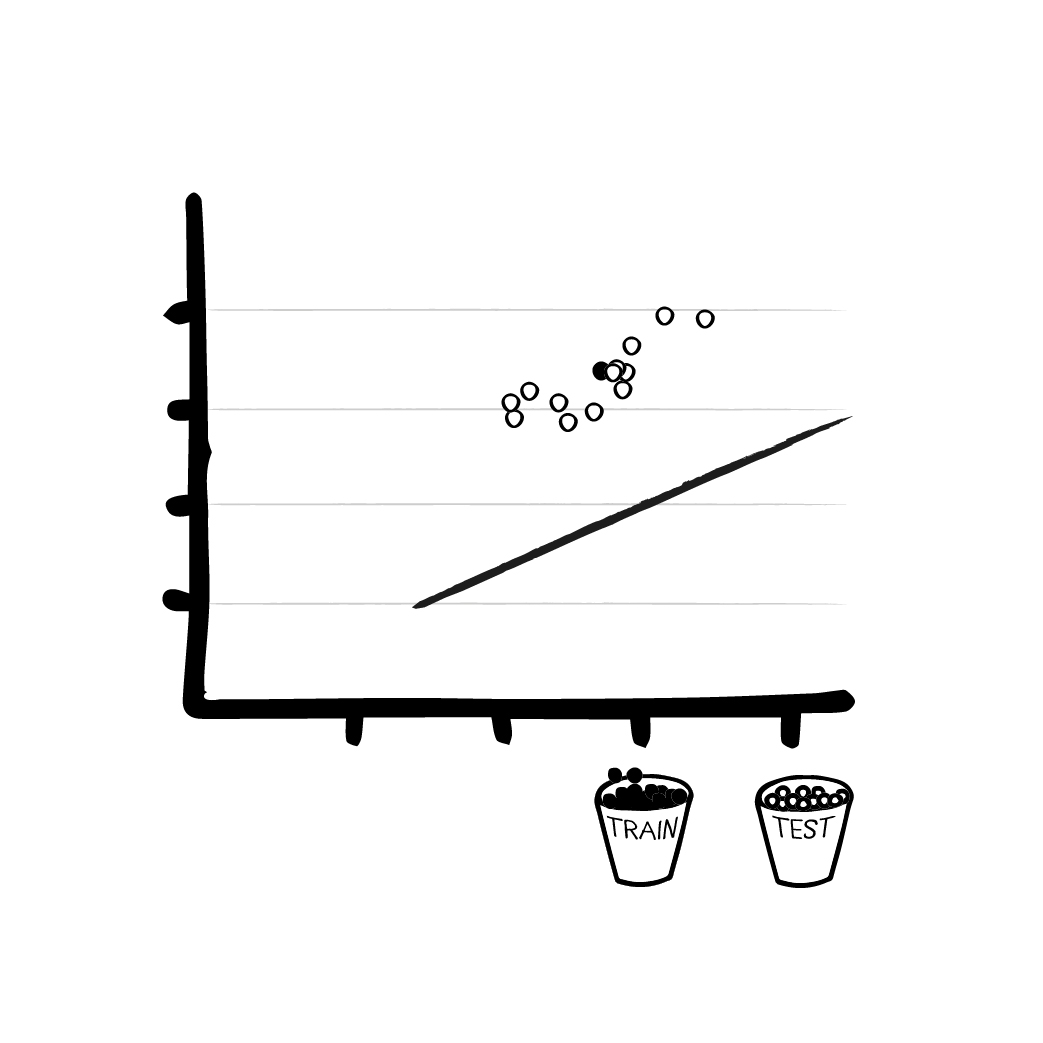
Schritt 3 - Das Trainings des ML Modells
Um mit dem eigentlichen Training zu beginnen, geben wir einen Satz Trainingsdaten in das Modell und berechnen das (vermutlich komplett falsche) Ergebnis. Das Modell rät die Ergebnisse zunächst auf’s Geratewohl, bzw. es benutzt die zufälligen Parameter, die wir ihm zu Beginn gegeben haben. Durch die zufälligen Werte in dieser anfänglichen Formel spuckt das Modell zunächst einfach sinnlose Zahlen aus. Aber immerhin haben wir ein Ergebnis, auch wenn es falsch ist.
Damit können wir nun einen Trick anwenden, nämlich den Fehler berechnen. Je größer die Menge der Testdaten ist, mit denen wir das Modell füttern, desto klarer wird unser Bild von den Fehlern und Abweichungen. Mit dem Inferenzalgorithmus berechnen wir, was die aktuelle Vorhersage des Modells ist. Der Trainingsalgorithmus vergleicht die Vorhersage mit dem tatsächlich richtigem Ergebnis in den Trainingsdaten und berechnet, wie sehr diese voneinander Abweichen. Anhand dieser Abweichung passt er die Parameter an, um die nächste Vorhersage zu verbessern. Er verbessert unsere lineare Funktion schrittweise, überprüft die Abweichungen und “registriert”, ob sie größer oder kleiner werden - je nachdem, wie die Parameter angepasst werden. Kurz: Er gibt an, wie wir unser Modell ändern müssen, damit es besser auf die Daten passt.
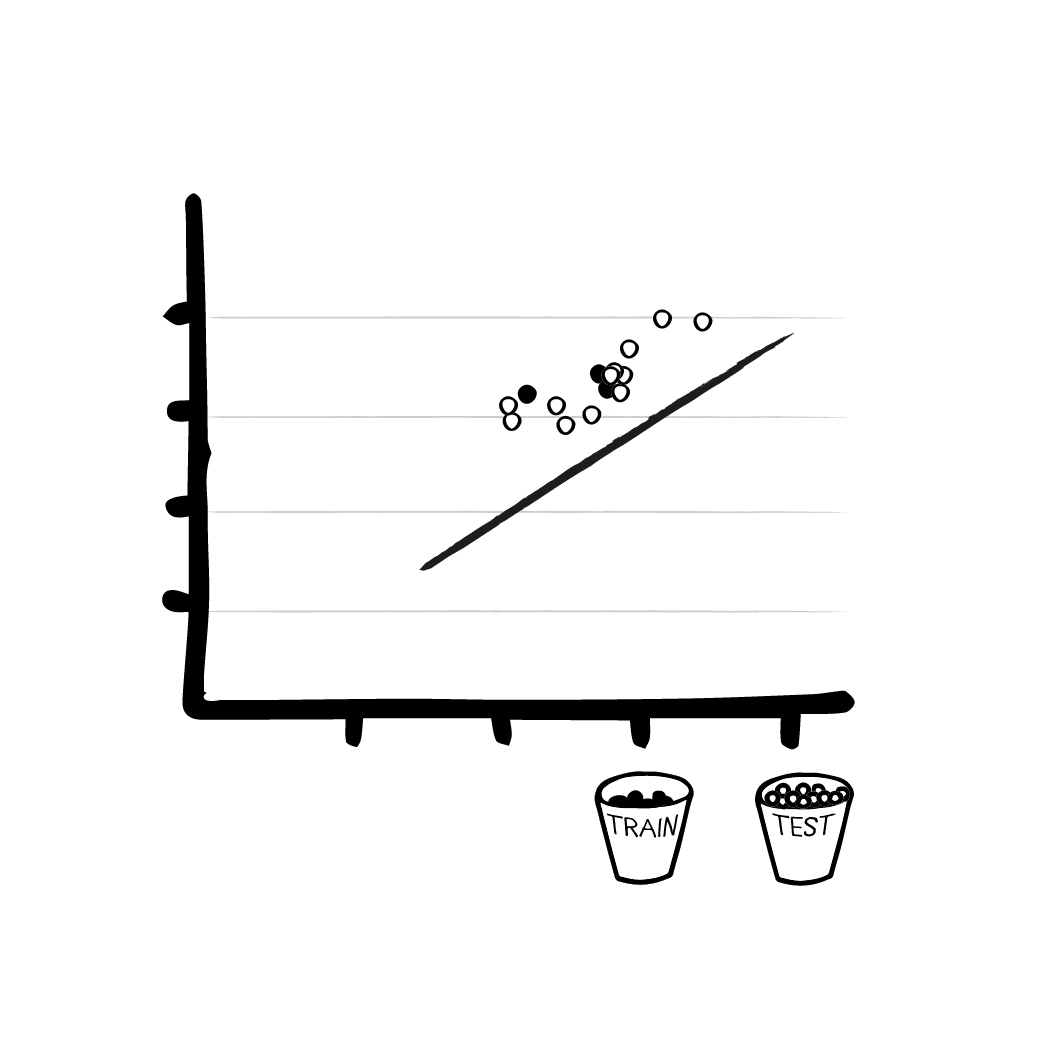
Schritt 4 - Überprüfung anhand der Testdaten
Ohne mathematisch zu tief einzutauchen, fassen wir an dieser Stelle zusammen: Mit den richtigen Formeln, den Trainingsdaten und der anfänglichen (falschen) Ausgabe des Modells kann der Algorithmus die Parameter des Modells optimieren, so dass die Lösung beim nächsten Mal ein wenig besser wird. Bei der linearen Regression in unserem Fall geschieht dies z.B. dadurch, dass die Linie näher an die Trainingspunkte geschoben wird.
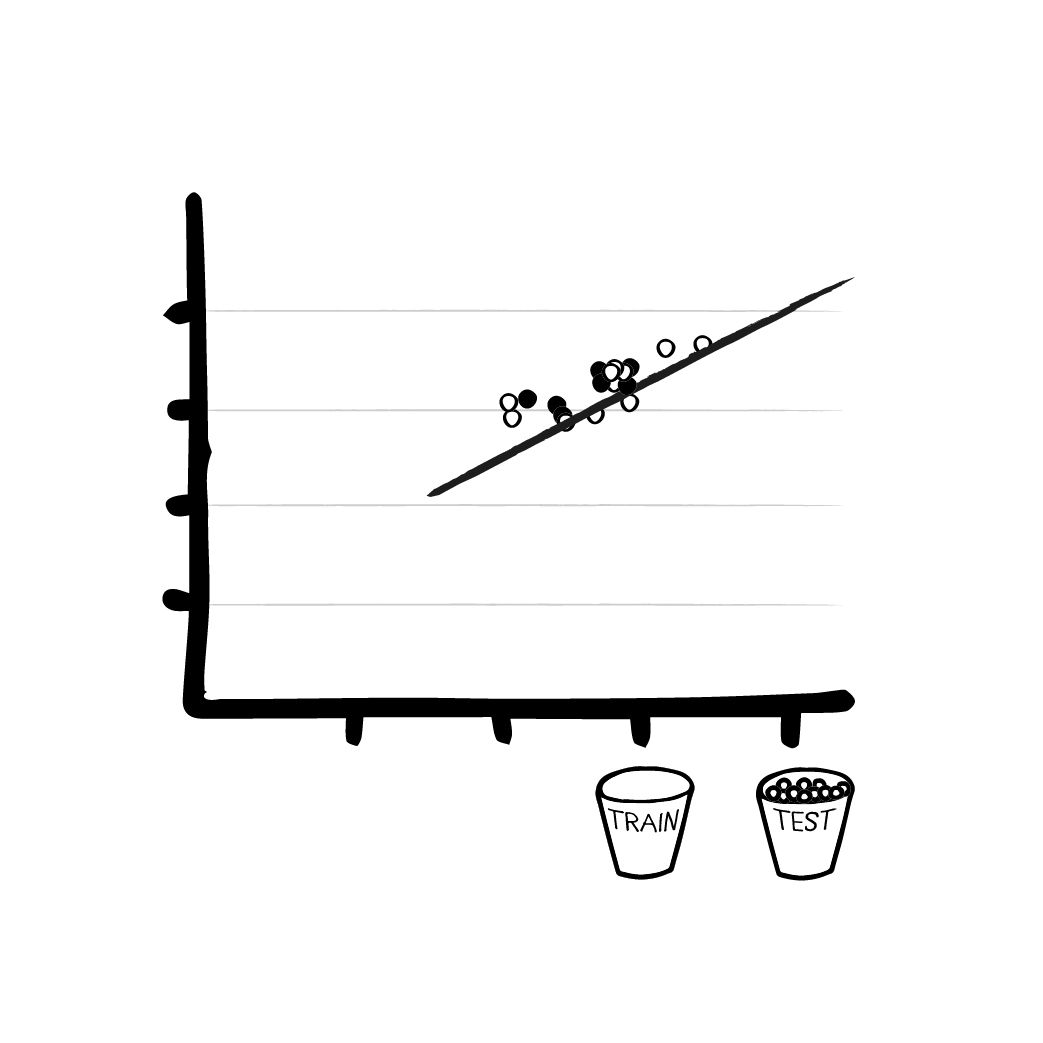
- Wir nehmen einen Teil der Trainingsdaten, berechnen das Ergebnis
- Wir berechnen den Fehler und beobachten, wie sehr das Ergebnis daneben liegt (z.B. einfach durch eine Subtrahieren vom gewünschten Ergebnis)
- Mithilfe des Fehlers und schlauer Mathematik (meist Ableitungen) berechnen wir, wie wir das Modell ändern müssen, damit der Fehler kleiner wird.
- Wenn wir mit dem Ergebnis zufrieden sind, hören wir auf - sonst gehen wir zurück zu 1. und wiederholen mit einem anderen Teil der Trainingsdaten.
Was aber, wenn wir alle Trainingsdaten benutzt haben und mit dem Ergebnis immer noch nicht zufrieden sind? Wir initiieren eine neue Epoche (siehe oben), nachdem wir die Daten in eine neue, zufällige Reihenfolge gebracht haben. Idealerweise gibt es so viele Daten, dass man nie an das Ende einer Epoche kommt, in der Praxis allerdings werden Daten oft mehrmals genutzt, das Modell also über mehrere Epochen trainiert. Bei einem Menschen ist das ähnlich: Auch wir müssen Vokabeln oft mehrmals (und möglichst in wechselnder Reihenfolge) durchgehen, bis wir sie gelernt haben.
Lineare Regression und ML bei “hochdimensionalem Input”
Vielleicht denkt jetzt der ein oder andere: “Das ist doch geschummelt! Eine Linie durch ein paar Punkte zu ziehen, ist doch keine KI!” Dabei muss man allerdings bedenken: Dasselbe Verfahren funktioniert nicht nur bei einer simplen zweidimensionalen Funktion und einem Eingabewert, sondern auch beim sogenannten „hochdimensionalen Input“.
Dieser pompöse Begriff weist lediglich darauf hin, dass man mehrere Eingabegrößen hat, und hat insofern mehr mit einer Steuererklärung als mit Science Fiction zu tun: Jede Steuererklärung hat eine mehrdimensionale Eingabe (Lohn, selbstständiges Einkommen, Anzahl der Kinder, …). Auch jeder Brief wird über mehrdimensionale Eingaben adressiert: Name, Nachname, Firma, Adresszusatz, Straße, Hausnummer, Postleitzahl, Stadt, Land - hier sind wir schon bei einem 9-dimensionalen Input!
Unser Grillen-Beispiel hatte lediglich eine Eingabe- und eine Ausgabegröße, so dass wir die Datensätze zweidimensional in Form einer Linie abbilden konnten. Doch dieselbe Mathematik, mit der man eine einfache Lineare Regression trainieren kann, funktioniert auch bei beliebig vielen Dimensionen. Man nennt das ganze dann zwar immer noch „linear“, weil die zugrundeliegende Mathematik immer noch linear ist - auch wenn es eine Zeichnung des Modells nicht mehr ist, bzw. das Modell gar nicht mehr ohne weiteres grafisch dargestellt werden kann.
ML in der Praxis: So einfach wie möglich, so kompliziert wie nötig
Wir stellen fest: Bei richtiger Vorverarbeitung kann so eine lineare Regression erstaunlich leistungsfähig sein. Daher ist dieser einfache Algorithmus auch heute noch praktisch relevant. Zum einen als Bestandteil komplexerer Systeme - wie wir später sehen werden, kommt kein neuronales Netz ohne lineare Regression aus -, zum anderen ist es beim Machine Learning oft so, dass einfache Verfahren oft besser funktionieren als komplexe. Die Qualität des Ergebnisses hängt in der Regel nämlich weniger vom Verfahren, sondern in erster Linie von den Lerndaten ab. Auch kann der Performancegewinn durch ein kompliziertes Verfahren so gering sein, dass sich der erhöhte Aufwand (Rechenzeit, Speicherverbrauch, Programmieraufwand, Fine-Tuning, …) für das komplexe Verfahren nicht wirklich lohnt.
In jedem Fall sind lineare Verfahren immer gut geeignet, um eine „Baseline“ festzulegen: Was ist mit minimalem Aufwand mit den vorhandenen Daten zu erreichen? Viele Projekte starten mit einem linearen Verfahren um spätere Resultate besser einschätzen zu können.
Natürlich gibt es eine Menge Dinge, die eine lineare Regression nicht kann - sonst bräuchte es kein Deep Learning und keine neuronalen Netze. Aber wie bei den zuvor vorgestellten klassischen KI Verfahren gilt: So einfach wie möglich, so kompliziert wie nötig. In einem realen Projekt gilt es, so ressourcensparend wie möglich das bestmögliche Ergebnis zu erreichen.
Wie also geht es weiter? Im nächsten Artikel werden wir uns weiter mit dem Machine Learning beschäftigen und betrachten, wie man ML Verfahren weiter kategorisieren kann und was ihre Stärken und Schwächen sind.