Methoden der klassischen KI
Im vorherigen Beitrag haben wir unsere anfängliche Definition von künstlicher Intelligenz um zwei Unterscheidungen erweitert: Unterschieden wird einerseits zwischen starker und schwacher KI (Terminator & Science Fiction vs. Status Quo), sowie zwischen klassischer KI und dem Machine Learning.
Wir erinnern uns: Die “klassische” KI versucht, Probleme mithilfe eines Top-Down-Ansatzes zu lösen (Beispiel: Schachcomputer). Das Machine Learning verfährt nach dem Bottom-Up-Prinzip und passt eine Vielzahl von Parametern schrittweise an, bis es die erwarteten Ergebnisse liefern kann. Derzeit ist vor allem das Deep Learning - ein Spezialfall des Machine Learning - in aller Munde. Um aber zu sehen, was denn nun das besondere daran ist, lohnt es sich, zunächst einen Blick auf klassische Verfahren zu werfen.
Auch wenn die großen Fortschritte zur Zeit im Bereich des Deep Learnings passieren, wird doch kein komplexes KI System - vom persönlichen sprachgesteuerten Assistenten bis hin zu selbstfahrenden Autos - ohne eine oder mehrere der folgenden Technologien auskommen. Wie so oft in der Softwareentwicklung besteht ein erfolgreiches Stück KI Software aus dem richtigen Zusammenspiel mehrerer Teile.
Die einfachste KI: Der „Vokabellerner“
Der sogenannte „tabellenbasierte Agent“ ist die einfachste denkbare KI: Alle richtigen Lösungen stehen der KI in Form einer Tabelle zur Verfügung, auf die er zur Lösung des Problems zugreifen kann.
Dieses erste und einfachste Beispiel stößt bei unseren Vorträgen und Veranstaltungen gerne auf Widerstand: „Das hat doch nichts mit Intelligenz zu tun!“ Allerdings ist es eine Technik, die auch wir Menschen verwenden - wenn auch wesentlich weniger effizient. Jeder, der schon einmal Vokabeln pauken musste, weiß das. Auswendiglernen ist ein Aspekt des menschlichen Verstandes - warum also nicht auch der einer künstlichen Intelligenz? Denn Auswendiglernen können Computer nun mal besonders gut.

Angenommen also, ich möchte eine KI Software erstellen, die ein bestimmtes Problem lösen soll. Und angenommen, dies funktioniert fehlerfrei, schnell und einfach mittels einer “simplen” Tabelle - wieso sollte ich nicht genau diese Lösung wählen?
Die eine oder andere fragt sich vielleicht, wo das „Können“ beim Bau eines solchen Systems liegt? Der Trick bei der Entwicklung ist in erster Linie, bei komplexen Problemen zu erkennen, welche Teilprobleme effizient und simpel mit einer Tabelle (oft auch „Lookup“ genannt) gelöst werden können. Setzt man den “Vokabellerner” in solchen Fällen ein, kann man einem komplexeren, mit mehr Aufwand zu erstellenden System Arbeit abnehmen und so die Effizienz des gesamten Systems verbessern. Tabellenbasierte Agenten können so z.B. nützlich sein, um ein neuronales Netz zu unterstützen: Man erweitert den Input eines Machine Learning Systems einfach um die Möglichkeit, einen Blick in die Tabelle zu werfen. Das lernende System kann sich so auf Ausnahmefälle fokussieren, da es nicht erst die gesamten Informationen aus der Tabelle lernen muss - diese stehen ihm ja bereits verlässlich zur Verfügung. So kann die Leistung des ganzen Systems gesteigert oder die Zeit, die zum Entwickeln und Trainieren gebraucht wird, verkürzt werden - im besten Fall beides.
Alternativ kann die Tabelle auch das Ergebnis des Lernens sein: Statt den Inhalt der Tabelle manuell zu bestimmen, lässt man ihn durch ein Machine Learning Verfahren „lernen“.
Ist deshalb jede Tabelle eine KI? Natürlich nicht, es kommt darauf an, wie sie eingesetzt wird. Ein so einfaches System ist natürlich meist nicht nützlich, aber wenn man ein KI Problem durch eine Tabelle aller Lösungen praktisch umsetzen kann, sollte man die eigene Eitelkeit, etwas „richtig intelligentes“ zu bauen, herunterschlucken. Ein tabellenbasierter Agent ist günstig, verlässlich und insbesondere sind seine Entscheidungen nachvollziehbar.
Ein Schritt komplizierter: Der Entscheidungsbaum
Entscheidungsbäume kennt man auch als Laie aus dem echten Leben: Dienstanweisungen, Verkehrsregeln, Spielregeln und die Steuererklärung sind Beispiele für Anweisungen, die sich prima als Entscheidungsbäume umsetzen lassen. Man beginnt mit einem Ausgangspunkt und kommt durch schrittweise Fragen, jede davon resultieren aus den vorherigen Antworten, zu einem Ergebnis, z.B. dem anzuwendenden Einkommenssteuersatz.
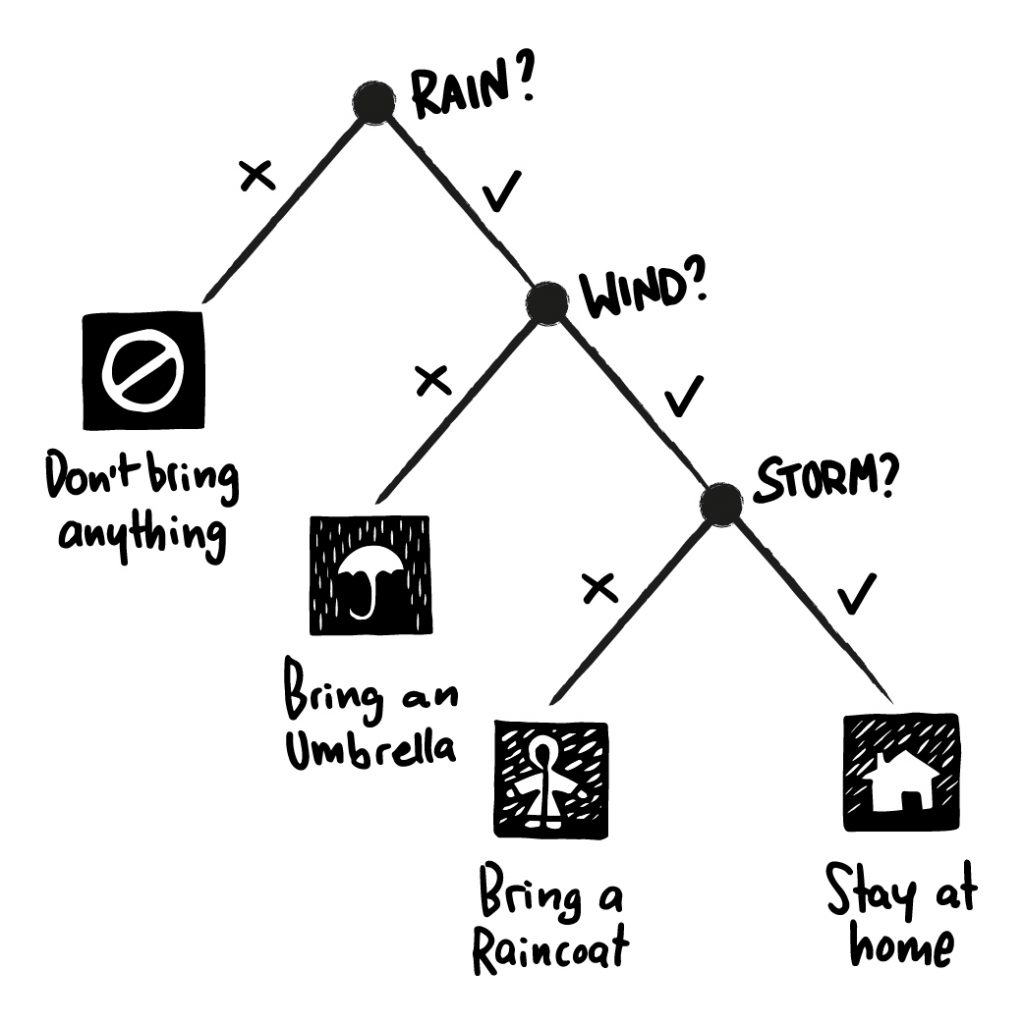
Diese Technik findet sich natürlich nicht nur bei KI Software, sondern z.B. auch beim Checkout in einem Online-Shop („Kreditkarte oder Rechnung“ - „Lieferung nach Deutschland oder in die EU“). Wie beim “Vokabellerner” und der Tabelle ist auch in diesem Fall also nicht gleich jeder Entscheidungsbaum eine KI. Einfache KI Probleme lassen sich aber durch Entscheidungsbäume (oft gerade in Kombination mit tabellenbasierten Agenten) gut lösen. Die Regeln für den Baum und der Inhalt von Tabellen werden dabei häufig von Experten für das zu lösende Problem aufgestellt. Man spricht in diesem Fall gerne von einem „Expertensystem“, da man versucht, das Wissen von Experten in Form von Regeln abzubilden.

Wie Tabellen haben auch Entscheidungsbaumverfahren den enormen Vorteil, dass ihre Entscheidungen gut nachvollziehbar sind. Regeln möglichst transparent und deterministisch anzuwenden - spätestens wenn man an selbstfahrende Autos denkt, erschließt sich der Vorteil einer so funktionierenden KI. Jeder möchte wohl verstehen und nachvollziehen können, welche “Entscheidungen” konkret den Kurs eines selbstfahrenden Fahrzeugs bestimmen.
Apropos selbstfahrende Autos. Wir haben bereits erwähnt, dass im Idealfall eine solche klassische KI mit modernen Verfahren kombiniert werden und so besonders effizient agieren kann. Im Falle eines selbstfahrenden Autos könnte das folgendermaßen aussehen: Das neuronale Netz entdeckt ein Stoppschild, der Entscheidungsbaum entscheidet sich dafür, anzuhalten. Und wie bei der Tabelle kann Machine Learning mit Entscheidungsbäumen kombiniert werden, indem die Struktur der Bäume gelernt wird. Das nennt man dann Entscheidungsbaumlernen. Der Vorteil: man muss den Baum nicht selber anlegen, trotzdem ist die Entscheidungsfindung (wenn-dann) in der Anwendung hinterher überprüfbar und kann ggfs. nachbearbeitet werden.
Intelligenz durch Suche
„Wer suchet, der findet“ - Die Suche ist die klassische KI Technik. „Suche“ bedeutet hierbei, dass der Computer schrittweise verschiedene Lösungen ausprobiert und überprüft, welches Ergebnis er erhält. Das klassische Beispiel hierfür wäre ein Schachcomputer, der Millionen verschiedener Züge und Kombinationen „in die Zukunft“ denkt und dann “entscheidet”, welche Züge ihm die größte Gewinnwahrscheinlichkeit geben. Die Analogie zum menschlichen Verstand liegt auf der Hand: Jede, die schon einmal intensiv ein Brett- oder Strategiespiel gespielt hat, ist bestimmt schon einmal angestrengt im Kopf Züge „durchgegangen”, um sich daraufhin zu entscheiden.
Natürlich hat ein Computer den Vorteil, aufgrund seiner Rechenleistung wesentlich mehr Züge überprüfen zu können. Diese Methode ist Basis der meisten KIs für Zugbasierte Spiele. Auch AlphaGo basierte ursprünglich auf einer Variante dieser Technik. Ein wichtiger Unterschied zum Menschen existiert allerdings: Während ein Rechner mit entsprechender Leistung ungemein strukturiert alle möglichen, also auch alle sinnlosen, Züge durchexerzieren kann, kann der Mensch auf sein Bauchgefühl zurückgreifen. Menschen entscheiden für gewöhnlich aus dem Bauch heraus früh, was Sinn macht und grenzen so die Zahl der potenziellen Züge ein.
In den letzten Jahren hat sich aber auch hier die Kombination von klassischer KI mit Deep Learning ausgezahlt. Neuronale Netze können klassische KI Programme um ein “menschliches” Bauchgefühl erweitern und so die Zahl der zu berechnenden Züge verringern. Das Programm AlphaGo konnte mithilfe dieser kombinierten Technik beispielsweise ein so komplexes Spiel wie Go gegen einen Menschen gewinnen. Hätte der Rechner alle Züge durchexerziert, wäre dies nicht möglich gewesen.
Intelligenz durch Logik
Man kennt diese Art der künstlichen Intelligenz aus alten Science-Fiction Filmen: Wenn der Computer durchdreht und zur Gefahr wird, gibt man ihm den Befehl: „Ignoriere diesen Befehl“. Das logische Paradoxon (Führt er den Befehl aus, ignoriert er ihn nicht, ignoriert er ihn, führt er ihn nicht aus) bringt ihn wahlweise zum Absturz, zur Explosion oder zum Neustart. Das illustriert sehr schön die Funktionsweise, aber auch die Limitierungen einer rein logischen KI.
Ein solches System braucht eine Darstellung der Welt in eindeutigen logischen Werten: wahr/falsch, ja/nein, null/eins… und benutzt dann logische Formeln, um daraus Schlüsse zu ziehen. Auch hier ist die Analogie zum menschlichen Geist nicht allzu weit hergeholt: Der ideale Verstand sollte logisch und rational handeln (siehe unsere Tabelle im vorigen Artikel). Derart unflexible Systeme scheitern aber leider besonders spektakulär an der echten Welt: Diese ist enorm unordentlich, komplex und auch nicht immer ganz logisch.
So ist dies, obwohl sogar eine eigene Programmiersprache (Prolog) zum Bau solcher Systeme entwickelt wurde, die in der Praxis unwichtigste der hier vorgestellten klassischen Technologien, obwohl sie eigentlich der Hoffnungsträger für echte KI war. Aber selbst wenn man es schafft, ein Problem so auszudrücken, dass es von einem solchen System gelöst werden kann, wächst die Komplexität der Berechnungen schnell exponentiell an, so dass bei nützlichen Anwendungen die Lösung schnell einige Milliarden Jahre auf sich warten lässt.
Logische Systeme sind derzeit daher nur von historischem Interesse, von einigen wenigen Nischenanwendungen einmal abgesehen. Aber wer weiß - vll. gelingt ja in ein paar Jahren der große Durchbruch, der Logik und Deep Learning verheiratet und wie die neuronalen Netze erhebt sich die Logik aus der Versenkung und Prolog-Programmiererinnen werden heiß gesucht (wir wetten allerdings nicht darauf).
Vorteile der klassischen KI
Der große Vorteil klassischer KI oder symbolischen KI besteht darin, dass die Entscheidung eines Systems genau nachzuvollziehen und zu verstehen sind. Auch braucht es keine großen Datenmengen, da die Systeme nicht (basierend auf viel Input) „lernen“, sondern die Entwicklerin ihr eigenes Wissen in das System „gießt“. Je nach Verfahren braucht es auch weniger Rechenpower (allerdings nicht immer), als für das Anlernen großer neuronaler Netze nötig ist.

Nach wie vor gibt es Aufgaben, bei denen eine klassische KI noch besser abschneidet. Dies tut sie besonders dann, wenn die Aufgaben sich gut durch Suchen formulieren lassen. Hybride Ansätze verschmelzen mittlerweile aber zunehmend klassische KI und Deep Learning. Ziel ist es, die Schwächen und Probleme der einen durch die andere auszugleichen - seien es das erwähnte “Bauchgefühl” oder die enorme notwendige Rechenleistung. Abgesehen von Nischenanwendungen wird es also immer schwerer, die komplexen KI Systeme der Gegenwart ohne weiteres dem einen oder anderen Ansatz zuzuordnen. Geschweige denn, daran Schwächen oder Stärken festzumachen.
Die letzte große Bastion der klassischen KI sind allerdings Computerspiele. Hier wird viel Rechenpower für die Grafik und Physik gebraucht und Echtzeitverhalten ist gewünscht, so dass die große Mehrheit von Computerspiel-Gegnern (noch) aus dem Lager der klassischen KI rekrutiert wird.
Nachteile der klassischen KI
Der größte Nachteil klassischer KI ist, dass sie für viele Problemstellungen aus der echten Welt schlicht und einfach nicht (oder nur sehr schlecht) funktioniert. Da wir bei symbolischen Verfahren unsere Lösungen in eindeutige klar umrissene Regeln (Tabellen, Entscheidungsbäume, Suchalgorithmen,Symbole …) gießen müssen, stoßen wir auf massive Hindernisse, wenn das Problem sich eben nicht so eindeutig beschreiben lässt. Interessanterweise ist dies gerade oft bei Dingen der Fall, die für einen Menschen einfach sind oder für die er ein Bauchgefühl entwickeln kann. Das klassische Beispiel hier ist das Erkennen von Gegenständen in einem Bild. Dies ist schon für kleine Kinder trivial, für Computer war dies jahrzehntelang ein unüberwindbares Problem.

Generell wird es für klassische KI immer problematisch, wenn man die Welt von Regeln und Definitionen verlässt und die „echte“ Welt betritt. Somit erfüllt sie heutzutage zunehmend nur noch die Rolle einer Hilfstechnologie für Machine Learning und Deep Learning.
Im nächsten Teil werden wir dann die deterministische und starre Welt der symbolischen KI verlassen und uns anschauen, wie Maschinen „lernen“ können.